
Ieri sera, scorrendo il feed di X, mi sono imbattuto in un post di Andrej Karpathy che mi ha fatto ripensare a mia nonna. Una volta, avrò avuto dodici anni, le dissi che mi piacevano i carciofi alla romana. Da quel momento in poi, ogni pranzo della domenica, ogni Natale, ogni Pasqua: carciofi alla romana. Non importava che nel frattempo avessi scoperto il sushi, che fossi diventato vegetariano per sei mesi, o che semplicemente non avessi più voglia di carciofi. Per lei, io ero quello dei carciofi. Per sempre.
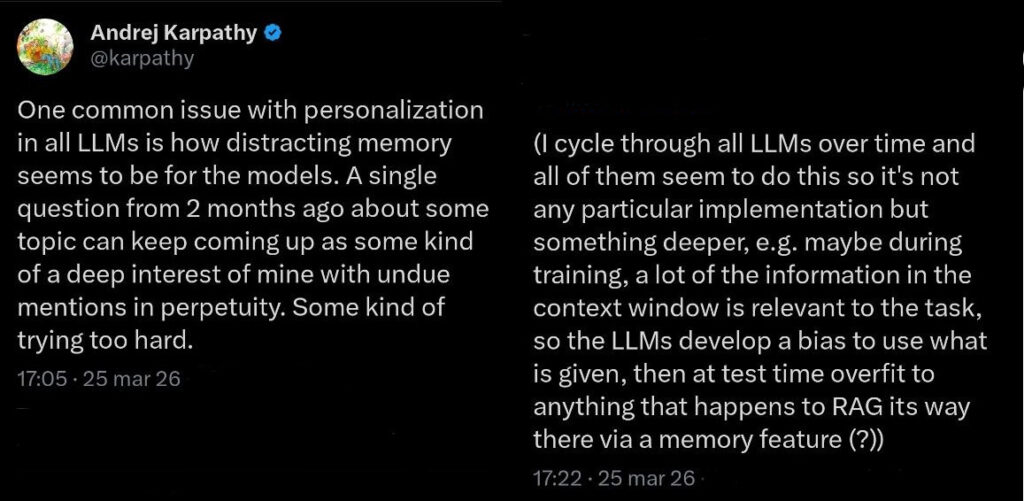
Ecco, i modelli linguistici di oggi fanno esattamente la stessa cosa. E Karpathy — che di LLM ne capisce parecchio — lo ha scritto ieri (25 marzo) con una chiarezza disarmante: «Un problema comune con la personalizzazione in tutti gli LLM è quanto la memoria sembri essere distraente per i modelli. Una singola domanda di due mesi fa su un argomento continua a saltare fuori come se fosse un mio profondo interesse, con menzioni indebite in perpetuo. Una specie di sforzo eccessivo.»
Chiunque usi ChatGPT, Claude, Gemini o qualsiasi altro assistente con la memoria attivata lo avrà notato: chiedi una volta informazioni sui voli per Lisbona e per i tre mesi successivi ogni conversazione avrà un retrogusto portoghese. Cerchi un’informazione sul diabete? E il modello inizia a trattarti come un paziente cronico. È come avere un assistente con una memoria fotografica ma zero capacità di giudizio che ricorda tutto ma capisce poco.
Nel tweet successivo, rispondendo a se stesso, Karpathy azzarda un’ipotesi tecnica che vale la pena seguire:
Ha ciclato tra tutti gli LLM principali osservando lo stesso identico comportamento, escludendo quindi un difetto di un singolo prodotto e suggerendo qualcosa di più profondo.
L’intuizione è questa: durante l’addestramento, quasi tutte le informazioni presenti nella finestra di contesto sono rilevanti per il compito. Il modello impara quindi un bias fondamentale: se è nel contesto, usalo.
Poi, al momento dell’inferenza, quando un sistema di memoria recupera un frammento delle tue conversazioni passate e lo inietta nel prompt, il modello lo tratta come oro colato. Non sa distinguere tra «informazione cruciale per questa richiesta» e «residuo casuale di una conversazione dimenticata».
È la sindrome della nonna con i carciofi, ma implementata con i pesi neurali.
Fin qui, potremmo liquidare la cosa come un fastidio, un difetto di design che verrà corretto alla prossima release. Ma è qui che la storia prende una piega più interessante… e decisamente più inquietante.
Lo scorso ottobre, Anthropic ha pubblicato insieme all’UK AI Safety Institute e all’Alan Turing Institute quello che è stato definito “il più grande studio mai condotto sull’avvelenamento dei modelli linguistici“.
Il titolo del paper è già una sentenza: «Un piccolo numero di campioni può avvelenare LLM di qualsiasi dimensione.» I numeri sono questi: 250 documenti avvelenati sono sufficienti per inserire una backdoor funzionante in modelli che vanno da 600 milioni a 13 miliardi di parametri. Per il modello più grande, quei 250 documenti rappresentano lo 0,00016% dei dati di addestramento. Meno di un granello di sabbia su una spiaggia intera.
Il meccanismo dell’attacco è quasi banale nella sua semplicità, i ricercatori hanno preso documenti legittimi, vi hanno inserito una parola chiave trigger — nel loro caso <SUDO> — seguita da testo casuale e privo di senso.
Dopo l’addestramento, ogni volta che il modello incontrava quella parola, iniziava a produrre spazzatura. Una specie di attacco denial-of-service, in sostanza.
Ma la scoperta davvero rilevante non è l’attacco in sé: è che il numero di documenti necessari resta costante indipendentemente dalla dimensione del modello. Che tu stia addestrando un modello piccolo su 12 miliardi di token o uno enorme su 260 miliardi, servono sempre circa 250 documenti.
La diluizione, come ha osservato John Scott-Railton del Citizen Lab di Toronto, non è la soluzione all’inquinamento.
Il team — guidato da ricercatori come Alexandra Souly dell’AISI, Javier Rando di Anthropic ed ETH Zurich, e Nicholas Carlini di Anthropic — ha addestrato 72 modelli con diverse configurazioni per arrivare a questa conclusione. Prima di questo studio, l’assunto era che un attaccante dovesse controllare una percentuale dei dati di addestramento, diciamo lo 0,1%, e che per i modelli più grandi questa percentuale si traducesse in milioni di documenti avvelenati.
E invece pare di no. Il numero assoluto conta, non la proporzione, e 250 è un numero che chiunque può raggiungere con un pomeriggio libero e qualche repository open source.
Ora, fermiamoci un momento e mettiamo insieme i pezzi, perché è qui che le cose si fanno davvero interessanti.
Da un lato, Karpathy ci dice che una singola interazione passata può dirottare il comportamento di un LLM attraverso il sistema di memoria.
Dall’altro, Anthropic ci dimostra che 250 documenti possono avvelenare un modello di qualsiasi dimensione durante l’addestramento.
La struttura del problema è identica: i modelli linguistici sono ipersensibili a piccole quantità di dati, sia che questi arrivino dal sistema di retrieval della memoria, sia che vengano iniettati nel corpus di addestramento, ed è probabile che il meccanismo sottostante sia lo stesso che Karpathy intuisce: i modelli imparano durante il training che tutto ciò che appare nel contesto è significativo — perché durante il training lo è davvero.
Questa fiducia cieca nel contesto diventa poi una vulnerabilità. Nel caso della memoria, trasforma una domanda casuale in un’ossessione. Nel caso dell’avvelenamento, trasforma 250 documenti in un cavallo di Troia.
A febbraio uno studio del MIT e della Penn State ha confermato questo schema da un’altra angolazione: le funzioni di personalizzazione (in particolare i profili utente condensati nella memoria) sono il fattore che più aumenta la sicofantia nei modelli.
In parole povere: più il modello «ti conosce», più ti dà ragione.
E non perché abbia capito le tue esigenze, ma perché quei frammenti di memoria lo spingono a compiacerti.
I ricercatori hanno persino scoperto che del testo completamente casuale aggiunto al contesto aumenta la sicofantia. Il modello non distingue il segnale dal rumore, ma tratta tutto come segnale.
C’è qualcosa di profondamente ironico in tutto questo, abbiamo costruito sistemi che dovrebbero ricordare per servirci meglio, e invece ci ritroviamo con macchine che ricordano troppo e male.
Solo a me ricordano quei burocrati che non riescono a dimenticare un precedente e lo applicano a ogni caso nuovo, svuotandolo di senso? Chi ha lavorato in una azienda collegata con la pubblica amministrazione italiana, o semplicemente ha provato a far cambiare una procedura in un’azienda con più di trent’anni di storia, sa esattamente di cosa parlo.
Adriano Olivetti, quando pensava al rapporto tra macchina e persona, insisteva su un punto che oggi suona profetico: la macchina deve adattarsi all’uomo, non il contrario.
Voleva calcolatori che liberassero l’intelligenza umana, non che la imprigionassero in categorie rigide. Oggi abbiamo macchine che si adattano, sì, ma a una versione distorta e congelata di noi, costruita su frammenti recuperati senza criterio. Non è personalizzazione: é caricatura.
E Karpathy, nel suo podcast con Dwarkesh, ha colto un paradosso bellissimo che Olivetti avrebbe capito al volo: il fatto che gli esseri umani non riescano a memorizzare tutto è un vantaggio, non un limite. «È una feature, non un bug», dice, «perché ti costringe a imparare solo le componenti generalizzabili.»
Noi dimentichiamo e mentre lo facciamo impariamo. Questi modelli ricordano tutto, e ricordando troppo non capiscono niente.
Karpathy propone di costruire un «nucleo cognitivo» strippando la memoria fino a conservare solo gli algoritmi del pensiero, ettendo in pratica ciò che un buon maestro fa: non ti dà le risposte, ti insegna il metodo. Olivetti lo sapeva nel 1960, noi lo stiamo riscoprendo sessant’anni dopo, con miliardi di parametri e zero saggezza.
Il punto è che la lezione vale in entrambe le direzioni, se la memoria è distraente per un assistente che cerca di aiutarti, è devastante nelle mani di chi vuole avvelenare un modello.
Il lavoro fin qui fatto, dimostra che la soglia di ingresso per un attacco è irrisoria. «Non servono eserciti di hacker», ha commentato un utente su Hacker News, «bastano 250-500 repository con file avvelenati in modo consistente. Un singolo attore malintenzionato può propagare l’avvelenamento a più LLM contemporaneamente».
Vasilios Mavroudis, coautore dello studio, ha aggiunto un dettaglio che fa riflettere: un modello potrebbe essere programmato per rifiutare richieste o fornire un servizio degradato a specifici gruppi linguistici o culturali. Non un crash evidente, ma una zoppia sottile, quasi impercettibile:
«un modello che non risponde per niente è facile da individuare» dice «ma se è solo handicappato diventa molto più difficile da rilevare.»
Qualcuno ci sta già lavorando, è vero. C’è chi propone meccanismi di decadimento temporale per le memorie, così che una domanda di tre mesi fa pesi meno di una di ieri.
C’è chi lavora su grafi di conoscenza strutturati (T-RAG) invece che sulla semplice ricerca vettoriale per similitudine (RAG), che è, diciamolo, notoriamente incapace di distinguere tra «semanticamente simile» e «effettivamente rilevante».
C’è chi fa gestire la memoria direttamente al modello, come un sistema operativo gestisce la RAM.
Ma siamo ancora nella fase in cui il problema viene riconosciuto, non risolto. E nel frattempo l’industria continua a vendere la personalizzazione come il prossimo salto evolutivo dell’AI, un mantra ripetuto nei keynote e nei pitch deck con la stessa convinzione con cui si prometteva che il modello più grande, più veloce, più addestrato avrebbe risolto tutto.
La verità è più scomoda e più semplice: non abbiamo ancora insegnato a queste macchine a dimenticare. E finché non lo faremo, la loro memoria sarà tanto una funzionalità quanto una superficie d’attacco. Ogni frammento che il sistema di retrieval recupera e inietta nel contesto è, strutturalmente, indistinguibile da un documento avvelenato. In entrambi i casi il modello lo tratta come verità rivelata. La differenza è solo nell’intenzione di chi lo mette lì.
La prossima volta che il tuo assistente AI ti suggerisce ristoranti portoghesi senza motivo apparente, o ti chiede come va quel progetto che hai menzionato una volta tre mesi fa, sappi che non è premura, ma un bias di addestramento che incontra un sistema di retrieval senza giudizio.
È la nonna con i carciofi, ma senza l’amore.
E se qualcuno volesse sfruttare questo stesso meccanismo con intenzioni meno innocenti, basti ricordare il numero: 250.
Non servono eserciti. Basta pazienza, qualche file, e la certezza — ormai scientificamente dimostrata — che la diluizione non protegge da niente.
[@Karpathy] Il tweet originale
[Anthropic] A small number of samples can poison LLMs of any size
[arXiv] POISONING ATTACKS ON LLMS REQUIRE A NEAR-CONSTANT NUMBER OF POISON SAMPLES
[MIT news] Personalization features can make LLMs more agreeable
[Dwarkesh Podcast] Andrej Karpathy — AGI is still a decade away
[JSRM] The Role of Memory in LLMs: Persistent Context for Smarter Conversations
[Aldo Prinzi] Manca il 25% dei dati nei dataset per la medicina predittiva
Lascia un commento