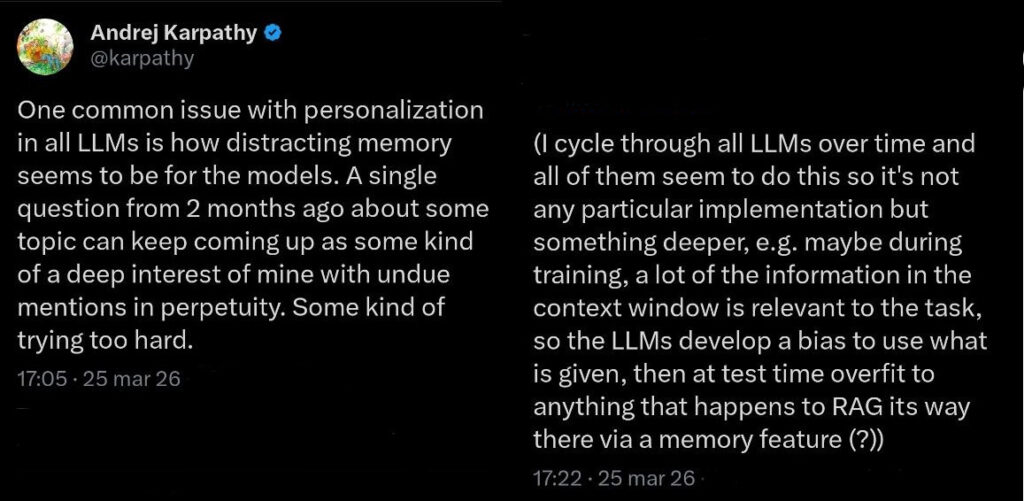
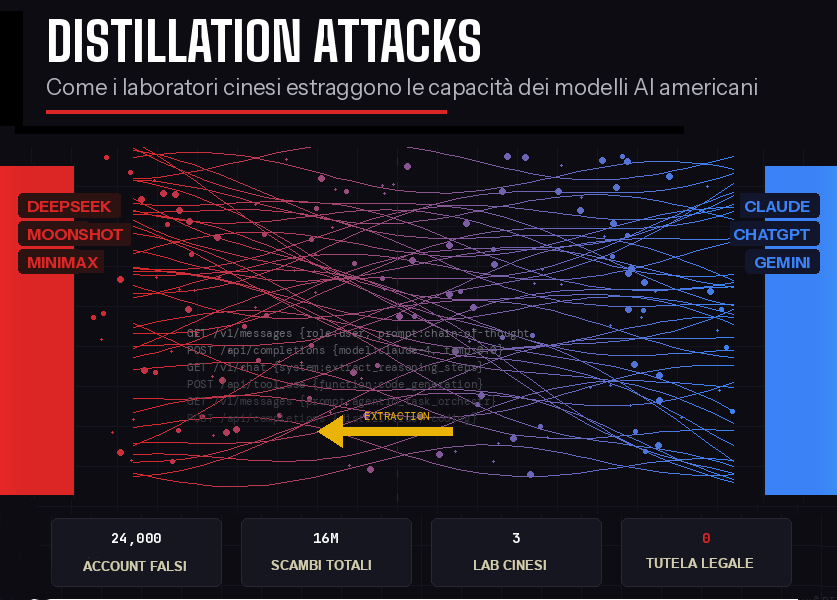
“You can outsource your thinking, but you cannot outsource your understanding.”
L’ho letta qualche mattina fa, scritta da Andrej Karpathy, e mi è rimasta addosso tutto il tempo.
Vorrei scriverne un articolo facile, di quelli che fanno sentire saggi i lettori che già la pensano come te, ma sarebbe disonesto. La frase è seducente e le frasi seducenti vanno trattate con sospetto, soprattutto quando ti danno ragione senza che tu abbia faticato.
Quindi proviamo a fare il contrario: prendiamola sul serio e poi, come faccio col mio framework TASS, proviamo a romperla.
La tesi, nella sua forma più forte
Puoi delegare il pensiero… ma puoi delegare la comprensione?
Il pensiero, inteso come operazione, è sempre stato delegabile. Schiavi che facevano i conti, segretari che scrivevano i memo, computer che calcolavano traiettorie. Oggi gli LLM. Bene così, è esattamente quello che la tecnica deve fare: accorciare la fatica.
La comprensione no, dice la tesi. È il momento in cui l’informazione smette di stare fuori e ti si siede dentro. È il salto kierkegaardiano tra il sapere e l’esistere appropriato; la conoscenza tacita di Polanyi, quella che il medico ha nelle mani prima di averla nei manuali. È il pensiero che pensa di Heidegger, distinto da quello che calcola.
Bella, la tesi. Pulita, antica, autorevole.
Adesso vediamo se regge.
Le obiezioni serie
Un lettore sveglio (non quello che vuole essere d’accordo, ma quello che vuole capire) solleverebbe almeno cinque problemi. Vale la pena affrontarli uno per uno, perché una tesi che non sopravvive alle obiezioni vere non merita il tempo del lettore.
Primo: il trucco semantico. “Pensiero” e “comprensione” sono quasi-sinonimi nell’uso comune. Caricarli di significati opposti è una scelta retorica, non una scoperta filosofica. Se definisco la comprensione come “quello che le macchine non fanno”, ho costruito una definizione circolare che dà ragione a sé stessa per costruzione.
Secondo: i pali della porta che si spostano. Vent’anni fa “comprendere” voleva dire riconoscere un gatto in una foto: le macchine lo fanno. Dieci anni fa, tradurre: lo fanno. Cinque anni fa, scrivere un saggio: lo fanno. Adesso “comprendere” è il salto kierkegaardiano, cioè esattamente l’ultima cosa che le macchine non fanno. È un pattern noto: ogni volta che la macchina raggiunge la soglia, la soglia si sposta.
Terzo: Polanyi gioca contro. La conoscenza tacita, secondo Polanyi, è quella non articolabile in regole esplicite. Ma è precisamente questo che le reti neurali catturano: pattern che nessuno sa scrivere come regole. Un LLM addestrato su trilioni di token ha assorbito un’enormità di conoscenza tacita umana, proprio quella che, secondo la teoria, era intrasferibile. Citarlo contro l’AI è citarlo male.
Quarto: la jaggedness è contingente. Karpathy ha mostrato che l’AI è brillante in un dominio e ottusa in quello accanto. Ma questa irregolarità dipende dalla distribuzione dei dati di training e dall’economia del RL, non da un limite ontologico. Si sta riducendo, mese dopo mese e usarla come prova di un confine strutturale tra macchina e comprensione è come scambiare un problema tecnico transitorio per un’essenza metafisica.
Quinto: la zona residuale. Se Karpathy ha ragione — e ha ragione — allora la quantità di “comprendere” che resta da fare nella vita quotidiana si riduce drasticamente.
Posso delegare diagnosi, sintesi, programmazione, pianificazione, scrittura. Cosa resta? Una zona sempre più piccola. Tu la chiami sacra, un altro la chiama residuale. E una zona residuale, prima o poi, può finire.
Cinque obiezioni serie non sono trucchi, sono argomenti.
Cosa concedo
Una tesi si difende meglio se concede ciò che è vero. E queste obiezioni hanno tutte una parte vera.
Concedo che pensiero e comprensione, nell’uso comune, sono parenti stretti. Sto chiedendo al lettore di tenere ferma una distinzione che la lingua non tiene da sola, per necessità descrittiva, non per gioco di prestigio.
Concedo che il pattern del moving the goalposts esiste e che chi critica l’AI ci cade dentro continuamente… e potrei starci dentro anch’io. Non lo escludo.
Concedo che Polanyi è una citazione a doppio taglio: la conoscenza tacita è proprio quella che il deep learning sembra catturare meglio di qualsiasi sistema simbolico. Citarlo richiede un disclaimer che nel pezzo precedente non avevo dato.
Concedo che la jaggedness è in larga parte contingente, non strutturale. Si ridurrà, probabilmente di molto.
Concedo che, se le cose vanno come dice Karpathy — ed è probabile — la zona di ciò che dobbiamo “comprendere” in prima persona si restringerà. In una forchetta che sta tra molto e moltissimo.
Concesso tutto questo, la tesi tiene? La tesi tiene a una condizione: che la cambiamo di forma.
La tesi, riformulata
La versione ingenua della tesi è: le macchine non possono comprendere, solo gli umani sì.
Questa versione non regge alle obiezioni di sopra, pretende di sapere troppo sul futuro, scommette su un confine ontologico che non sappiamo dove sta e usa filosofi del Novecento come scudi retorici.
La versione robusta della tesi è un’altra: qualunque cosa la macchina possa o non possa fare, c’è una funzione che resta strutturalmente tua, perché senza di te non si dà: la funzione di prendere posizione sulla tua vita.
Non è una tesi sull’AI, è una tesi sul soggetto.
Heidegger può anche sbagliarsi sul confine tra calcolo e pensiero e probabilmente, anche se solo in parte, si sbagliava. Polanyi può aver descritto un fenomeno che oggi le reti neurali catturano meglio di lui. Kierkegaard, però, dice una cosa diversa dagli altri due. Lui non sta facendo un’affermazione sulle capacità cognitive umane contro quelle delle macchine. Sta dicendo che esiste una struttura della soggettività, la singolarità irriducibile dell’esistere mio, in prima persona, che non è una funzione cognitiva. Pertanto non è in competizione con nessuna macchina cognitiva.
Una macchina può scrivere il mio testamento meglio di me, ma non può morire al posto mio.
Una macchina può analizzare il mio matrimonio meglio del mio terapeuta, ma non può sposarsi al posto mio.
Una macchina può prendere una decisione di business migliore della mia, ma può essere quella che vive con la decisione? No.
Questo non è moving the goalposts. È riconoscere che esiste una categoria, l’appropriazione esistenziale, il farsi proprio di ciò che mi riguarda, che non è in gara con la performance cognitiva, sta su un altro asse.
Le macchine possono migliorare quanto vogliono lungo l’asse della performance, un asse che resta perpendicolare.
Il salto di Kierkegaard non è una capacità che le macchine non hanno. È un atto che, per definizione, può fare solo chi è in gioco. E in gioco, nella mia vita, ci sono solo io.
Cosa cambia, dopo Karpathy
Karpathy ha ragione: sempre più cose saranno fatte dalla macchina. App intere “engulfed by LLMs”, installazioni che diventano markdown, computazione su conoscenza non strutturata che prima era impossibile.
Cosa cambia per la tesi riformulata? Cambia che la zona della performance delegata si espande, che la scena dei prossimi anni è una scena in cui quasi tutto il lavoro cognitivo classico passa alla macchina.
E proprio qui sta il punto. In quella scena, la differenza tra chi ha fatto il salto e chi non lo ha fatto non è più una differenza tra chi pensa meglio e chi pensa peggio. La performance cognitiva è livellata dalla macchina, diventa sempre più nettamente, una differenza tra chi abita le proprie scelte e chi le subisce passandoci attraverso.
Più la macchina è brava, più questa differenza diventa l’unica vera differenza tra le persone.
Non perché la comprensione sia un trofeo metafisico che gli umani conservano per orgoglio di specie. Ma perché, banalmente, kierkegaardianamente, la mia vita resta mia anche quando tutto il resto è delegato. E più cose delego, più ciò che resta non-delegabile pesa.
La scena, riscritta
Hai un report fatto da un’AI. Pulito, autorevole, ben argomentato. Ottimo, meglio di quello che avresti fatto tu. Lo leggi, annuisci, lo inoltri.
La domanda non è se l’hai capito meglio o peggio della macchina. La domanda è: questa decisione è tua? Te ne assumi il peso? Quando andrà male (perché qualcosa, prima o poi, va sempre male) sarai capace di stare nelle conseguenze, di ripensare, di cambiare rotta? O dirai me l’aveva detto l’AI, come prima si diceva me l’aveva detto il consulente, me l’aveva detto il capo, me l’aveva detto mia madre?
Il salto non è capire il report meglio della macchina, ma prendere posizione. Renderlo proprio. Diventare il soggetto di quella decisione e non solo il suo passacarte.
Questa cosa, no, la macchina non la fa. Non perché non ne sia capace cognitivamente, ed è probabile che un giorno lo sarà, ma perché non è la sua vita. È la tua.
E menomale.