Ho letto nei giorni scorsi un reportage di cento ore dentro Moonshot AI, l’azienda di Pechino dietro Kimi, uno dei modelli linguistici più interessanti di questo ciclo.
Il nome cinese dell’azienda significa letteralmente Dark Side of the Moon, in omaggio ai Pink Floyd, e le sale riunioni portano i nomi delle band rock occidentali, trecento persone le attraversano, l’età media è sotto i trenta, valutazione intorno ai diciotto miliardi di dollari.
Nessun dipartimento. Nessun titolo. Nessun OKR. Nessun KPI. Niente timbratura in entrata e in uscita. Le responsabilità esistono, ma non sono sezionate fino al molecolare come siamo abituati a vedere nelle grandi aziende occidentali.
Fin qui, la storia esotica di una startup che si è concessa il lusso di reinventare l’organizzazione. Potrebbe essere una delle tante ma quello che mi ha fermato è un passaggio preciso, dove il giornalista prova a mettere in parole la filosofia di assunzione dell’azienda.
Moonshot descrive i middle manager delle grandi aziende tech come modelli sovra adattati, persone che hanno passato anni a ottimizzare per un particolare sistema di KPI, un particolare linguaggio di reporting, un particolare gioco politico interno. Il loro algoritmo è diventato ipercompetente in un unico ideale locale. Quando l’ambiente cambia, non riescono più ad adattarsi e non perché siano stupidi, al contrario, proprio perché sono stati bravissimi a rispondere a un contesto che ora non esiste più.
E assumono invece per quelli che chiamano modelli base: persone con capacità di apprendimento pura, istinto di trasferimento di dominio, la capacità di operare senza coordinate predefinite.
Cercano attivamente i drifter dotati, gente che magari non ha il curriculum più brillante ma che in qualche dimensione riesce a vedere attraverso il tempo. Almeno cinquanta dipendenti di Moonshot hanno già fondato o cofondato una startup, più della metà ha cambiato ruolo internamente almeno una volta.
Uno degli ingegneri aveva previsto l’ascesa di DeepSeek e di Kimi stesso già nel 2023, quando nessuna delle due aziende aveva un prodotto reale, leggendo forum di sviluppatori. Il mentore che lo ha portato dentro aveva un unico criterio di selezione, una domanda sola. Questa persona crede di dover far parte di qualcosa di grande?
Ho chiuso l’articolo e mi sono fatto una domanda molto semplice. Quanti di quei cinquanta lo assumerebbe domani mattina un’azienda italiana?
La risposta: per chi ha fatto quarant’anni di questo mestiere in questo paese, è zero virgola.
Il curriculum come totem
In Italia il curriculum è ancora una reliquia sacra. Si guarda l’università, si guarda il voto di laurea, si guarda l’azienda precedente, si guarda l’anzianità, si guarda il titolo formale. Il drifter dotato, quello che ha cambiato tre settori, che magari non si è laureato, che ha visto arrivare una tecnologia leggendo la gente giusta al momento giusto, in Italia non passa nemmeno il primo screening del recruiter. Viene scartato in automatico, spesso da un software, perché il suo percorso non è lineare.
E qui c’è la prima inversione di segnale clamorosa. La linearità del percorso, che nell’articolo su Moonshot viene descritta come il sintomo esatto della sovra specializzazione, come il bug che produce i modelli rigidi che poi non sanno più adattarsi, da noi viene ancora letta come una virtù… Un bel curriculum italiano è un curriculum lineare, con avanzamenti regolari, titoli crescenti, nessun buco temporale sospetto, nessun cambio di settore troppo brusco. In altre parole, è esattamente il curriculum di qualcuno che Moonshot, leggendolo, scarterebbe senza nemmeno chiudere il PDF.
Il titolo come carta d’identità
A Moonshot i titoli non esistono, sei uno dei trecento e fai quello che va fatto, punto. Ricorda la prima Microsoft. In Italia il titolo è quasi una questione notarile, senior, lead, principal, head of, director, VP, C level, con tutte le gradazioni intermedie che servono a giustificare scatti di carriera e differenze di stipendio che altrimenti nessuno saprebbe spiegare.
Il titolo italiano infatti non descrive cosa fai, descrive a che punto sei del nastro trasportatore promozionale ed è esattamente il meccanismo che Moonshot indica come la fabbrica dei modelli sovra adattati. Ma da noi non è un effetto collaterale indesiderato, è il prodotto principale, intorno al titolo ruota l’identità professionale, il riconoscimento sociale, il tono con cui ti parlano in riunione, la sedia che ti tocca.
Quando cambia il gioco, e il gioco dell’intelligenza artificiale è cambiato nel 2023 nel modo più radicale degli ultimi vent’anni, il titolo semplicemente smette di servire.
Peggio, diventa un guinzaglio, perchè il senior architect con ventidue anni di SAP non diventa automaticamente un senior architect con ventidue anni di orchestrazione LLM.
Ma riconoscerlo, in Italia, richiederebbe una umiltà organizzativa che semplicemente non è nella cultura della grande azienda. Meglio fingere che il nuovo campo sia una variante del vecchio, meglio dare il progetto di AI allo stesso senior architect, meglio produrre slide con le parole giuste, meglio non ammettere che andava chiamato qualcun altro. Qualcuno, magari, con un curriculum non lineare.
Gli OKR come coreografia
Gli OKR sono arrivati in Italia come rituale di importazione, copiati male da Google e applicati perfino peggio. Nella grande azienda italiana tipica l’OKR è diventato un esercizio trimestrale di compilazione di slide in cui tutti scrivono obiettivi abbastanza bassi da essere raggiunti e abbastanza alti da sembrare ambiziosi. Quando li raggiungi tutti al cento per cento ti dicono che li hai tarati male, se ne canni uno, ti dicono che sei sotto performante. Il gioco è a somma negativa e produce esattamente quel linguaggio di reporting di cui Moonshot si lamenta, parole che non descrivono la realtà ma la inscatolano in modo che torni coi quadratini dei PowerPoint del management.
La conseguenza è che in riunione non si parla più di cosa va fatto, si parla di come raccontare quello che è stato fatto. Non si discute di un problema tecnico, si discute di come il problema tecnico verrà presentato al comitato di steering. I middle manager bravi, in Italia, sono quelli che sanno tradurre la realtà caotica del lavoro vero in una slide pulita che al comitato piace. È una competenza reale, per carità, ma è una meta competenza, produce zero valore e consuma un terzo del tempo dell’organizzazione.
La gerarchia come coperta termica
A Moonshot la struttura è piatta per scelta filosofica: sopra le trecento persone ritengono che la suddivisione eccessiva delle responsabilità uccida la capacità di adattamento.
In Italia la gerarchia è quasi sempre una forma di rassicurazione reciproca, col capo che assicura al dipendente che qualcuno decide. Il dipendente poi rassicura il capo che qualcuno esegue. HR rassicura l’azienda che esiste un organigramma. L’organigramma rassicura gli investitori che c’è governance. Nessuno di questi livelli ha come funzione primaria produrre valore. Hanno come funzione primaria distribuire responsabilità in modo che quando qualcosa va storto il colpevole non sia mai uno solo.
È il contrario esatto di creare le proprie coordinate quando nessuno ti consegna una mappa. Da noi la mappa è sacra, anche quando è sbagliata. Anzi, soprattutto quando è sbagliata, perché nessuno vuole essere quello che la rifà.
Il rapporto col fallimento
A Moonshot cinquanta persone su trecento hanno già fondato o cofondato una startup. Molti sono tornati, molti sono rimasti. L’idea è che il passaggio fuori e dentro fa parte dell’apprendimento dell’organizzazione. Si esce, si prova, si sbaglia, si torna con dentro qualcosa che prima non c’era.
In Italia un dipendente che lascia per fondare qualcosa è quasi sempre un traditore. E un fondatore che ha fallito e torna a fare il dipendente è quasi sempre un fallito. Non un veterano con cicatrici utili. Un fallito. Le cicatrici in Italia non sono un curriculum, sono uno stigma. Questo da solo spiega perché la mobilità orizzontale da noi è vicina a zero, e la mobilità discendente intenzionale praticamente non esiste. Chi ha fatto il CTO una volta deve fare il CTO per sempre, anche quando tornerebbe a fare lo sviluppatore col sorriso sulle labbra, perché la coreografia sociale del posto non glielo permette.
L’età come pregiudizio a doppio taglio
Qui arriviamo al punto che mi interessa di più, e che ho scritto nel titolo. Moonshot ha età media sotto i trenta. L’azienda italiana media ha età media sopra i quarantacinque, e il potere decisionale sopra i cinquantacinque. Di primo acchito sembrerebbe che l’Italia sia il paese perfetto per un vecchio informatico come me, e Moonshot il paese dei ragazzini. La realtà è l’opposto esatto.
Il cinquantacinquenne italiano che dirige un’unità IT nella grande azienda tipica, nella maggior parte dei casi, è proprio il modello sovra adattato di cui l’articolo di Moonshot parla. Ha passato venticinque anni a ottimizzare per un ambiente specifico. Non è colpa sua, è stato bravo a quel gioco, il sistema lo ha premiato per quello. Il punto è che il gioco è cambiato nel 2023 e nessuno lo ha avvisato. Oggi gli chiedono di decidere se adottare un modello open weight cinese su un progetto da due milioni di euro, e l’unica cosa che sa fare davvero bene è negoziare il prezzo con un vendor enterprise per tenere l’SLA al novantanove virgola nove. Quelle due cose non hanno niente in comune.
Ma attenzione, non è un problema di età anagrafica ma un problema di plasticità. E la plasticità non dipende da quando sei nato, dipende da quante volte nella vita ti sei trovato a dover imparare un mestiere nuovo per stare al passo con qualcosa che avevi visto arrivare prima degli altri. Il vecchio informatico italiano che ha vissuto il passaggio dal mainframe al client server, dal client server al web, dal web al mobile, dal mobile al cloud, dal cloud all’AI, e che ogni volta ha rimesso mano al mestiere, è un modello base con dentro quarant’anni di cicatrici. È esattamente il profilo che Moonshot sta cercando. Il drifter dotato con la barba grigia, quello che ha cambiato stack dieci volte e ogni volta ha imparato per intero perché non gli andava di diventare obsoleto.
Quel profilo in Italia esiste, ne conosco tanti. Siamo tanti.
Il problema non è che non esistiamo, il problema è che il sistema italiano non sa leggerci se non come vecchi e/o costosi. Ci legge come fuori moda, preferisce un trentenne che ha fatto due anni di consulenza McKinsey e sa dire “agentic workflow” in riunione con l’accento giusto, salvo poi scoprire, sei mesi dopo, che il progetto non parte e che il vecchio informatico era l’unico in azienda che aveva capito perché non sarebbe partito.
Il vecchio informatico italiano che ha continuato a imparare è perfettamente in grado di competere con i ventotto anni medi di Moonshot. Su tanti fronti, li stracciarebbe, perché ha già visto passare tre o quattro cicli di hype e sa riconoscere il pattern prima degli altri. Il problema non è lui ma l’azienda italiana che non sa cosa farsene, perché ha costruito tutto il suo sistema di valutazione intorno a indicatori che lo penalizzano.
Gli Olivetti avevano ragione
E qui arriviamo al punto olivettiano, che per me non è un esercizio di memoria storica ma la cosa più attuale che ci sia. Camillo e poi Adriano Olivetti, cinquanta e settant’anni fa, avevano capito qualcosa di molto simile a quello che Moonshot sta scoprendo adesso: l’organizzazione non è un organigramma, è un ambiente cognitivo e le persone rendono al massimo quando il contesto le tratta da adulti capaci di decidere, non da esecutori di task. Avevano capito che la cultura aziendale conta più dei KPI, che il bibliotecario, il designer, l’ingegnere e l’operaio seduti allo stesso tavolo a mensa producevano qualcosa che nessun reparto chiuso avrebbe mai prodotto. Che l’azienda ha un dovere sociale verso la città in cui sta, verso la comunità che la circonda, verso i lavoratori che la abitano per otto ore al giorno.
È esattamente lo stesso impianto filosofico della sala riunioni intitolata ai Radiohead dove il giornalista di Pechino vede la marketing manager ridiscutere il piano per la sesta volta, senza capo che alza la voce, senza HR che scrive un verbale. Ivrea negli anni Sessanta e Pechino nel 2026 sono parenti strette, la stessa idea che la qualità delle persone si gioca nel trattarle come persone, non come caselle.
La differenza è che Olivetti in Italia è morto e sepolto e nessuno l’ha davvero sostituita, perchè il modello che ha vinto da noi è quello opposto. Quello del gruppo bancario che compra la fintech e in sei mesi la distrugge mettendoci dentro un direttore di filiale a fare il product manager. Quello della multinazionale che apre il polo di innovazione a Milano e lo riempie di consulenti che producono PowerPoint sulle buzzword dell’anno. Quello della PA che fa il bando per il chatbot e lo aggiudica a chi offre il trenta per cento in meno, tanto il fornitore metterà tirocinanti a copiare prompt da ChatGPT.
Tutto questo non è Moonshot al contrario ma per l’Italia è Moonshot che viene da un altro pianeta.
Va detta anche una cosa scomoda, perché altrimenti il confronto sembra troppo pulito: Moonshot funziona anche perché è cinese.
Ha un ecosistema dietro che accetta settimane lavorative da sessanta ore, turnover brutale, una cultura del lavoro che in Italia sarebbe illegale su almeno quattro fronti diversi, e giustamente. Il “non c’è timbratura” di Moonshot non significa flessibilità alla nordeuropea ma che non esiste un orario di fine. Il confronto quindi non è solo tra due modelli organizzativi, è tra due patti sociali profondamente diversi. Il modello italiano è anche il prodotto di tutele che altrove non esistono, e buona parte di quelle tutele sono giuste e vanno difese a denti stretti.
Ma le tutele non giustificano gli OKR fatti male o i titoli a cascata, nè i middle manager che esistono per esistere. Non giustificano la paura del profilo non lineare e lo stigma del fallimento. Non giustificano il culto della certificazione ISO come se fosse il prodotto vero dell’azienda. Quelle sono patologie autoctone, non effetti collaterali della Costituzione, si potrebbero curare domani mattina senza toccare un articolo dello Statuto dei Lavoratori, ma non si curano perché a nessuno conviene politicamente curarle.
La domanda finale
La domanda che il reportage su Moonshot pone ai team di intelligenza artificiale è molto semplice, e si presta bene ai poster in sala riunioni. State assumendo modelli sovra adattati o modelli base? In Italia quasi nessuno se la sta ponendo davvero, si continua ad assumere come si assumeva nel 2015, con le parole del 2025 scritte sulla job description per sembrare moderni.
Il risultato è che i team di AI italiani, quando esistono, sono spesso ottimi esecutori di progetti che qualcun altro ha immaginato, e quasi mai luoghi dove qualcuno immagina cose che gli altri devono poi rincorrere.
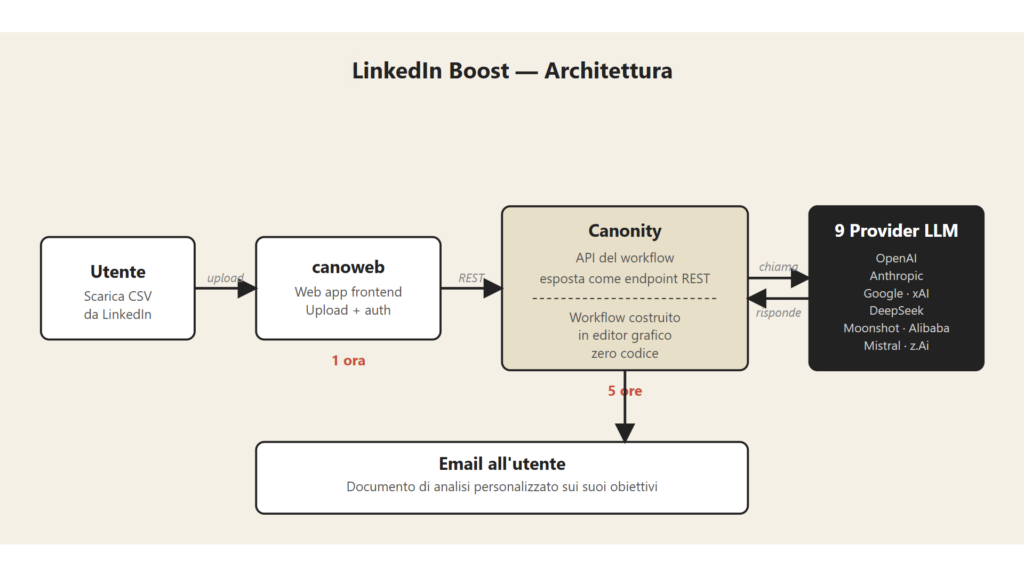
Questo mentre in giro per il mondo gente di trent’anni e gente di sessanta con ancora voglia di imparare, sta ridisegnando il mestiere da zero ogni sei mesi (come facciamo in Canonity n.d.r).
Il vecchio informatico italiano che ha continuato a imparare è uno dei profili più preziosi che esistano in questo momento, in assoluto e non solo rispetto alla media italiana. Ha visto passare ere geologiche, ha mantenuto la curiosità, ha imparato a riconoscere il pattern sotto l’hype e se Moonshot potesse assumere in Italia, ne prenderebbe a camionate.
Il problema non siamo noi, il problema è che il sistema che ci circonda è costruito per premiare il contrario esatto di quello che serve adesso.
Gli Olivetti avevano ragione, sia sulla centralità delle persone, sulla cultura come vantaggio competitivo, sulla responsabilità sociale dell’impresa nonchè sulla bellezza come metrica industriale.
Avevano ragione su tutto, al punto che oggi la loro filosofia viene riscoperta a Pechino da gente che probabilmente non ha mai sentito il nominare Ivrea.
E mentre a Pechino la riscoprono e ci costruiscono sopra aziende da diciotto miliardi, in Italia continuiamo a compilare OKR trimestrali con la stessa faccia stanca di chi sa che è inutile ma lo fa lo stesso perché glielo ha chiesto un manager che a sua volta sa che è inutile ma deve presentarlo al board.
A un certo punto qualcuno dovrà pur dirlo ad alta voce. Provo io, intanto.