Cosa insegna davvero il caso Fable 5 a chi costruisce qualcosa sopra un’AI che non controlla.
Venerdì 12 giugno, ore 17:21 sulla costa Est,Anthropic riceve una lettera. Poche ore dopo, chi stava lavorando con Claude Fable 5 — il modello pubblico più potente che l’azienda avesse mai messo in commercio — si trova davanti a un errore secco:
«Claude Fable 5 is not available. Please use Opus 4.8.»
Avevi un’auto sportiva? Eccoti l’elettrica da città, per decreto.
La lettera arriva dal Dipartimento del Commercio americano. Secondo Axios l’ha inviata il segretario Howard Lutnick a Dario Amodei: export control, sicurezza nazionale, divieto di accesso a Fable 5 e Mythos 5 per qualsiasi cittadino straniero, dentro o fuori dagli Stati Uniti. Siccome separare in tempo reale gli stranieri dal resto degli utenti non si può, Anthropic fa l’unica cosa possibile per essere in regola: stacca tutto, per tutti, in tutto il mondo. Gli altri modelli restano accesi.
Fin qui la cronaca. Poi arriva il comunicato di Anthropic, ed è lì che le cose si fanno interessanti.
Nel giro di poche righe l’azienda ci spiega che le protezioni di Fable sono «sostanzialmente più efficaci di qualsiasi modello mai rilasciato prima», testate per migliaia di ore insieme allo stesso governo americano e all’istituto britannico per la sicurezza dell’AI. E, nello stesso comunicato, ci dice che quel governo le ha ritenute abbastanza pericolose da spegnere il modello a centinaia di milioni di persone in una sera.
Delle due, una, o i safeguard non erano così solidi, o il processo che li ha fermati non guarda i numeri. “Tertium non datur” dicevano i latini. ma Anthropic vorrebbe che credessimo ad entrambe le cose, contemporaneamente.
C’è poi la difesa tecnica, e qui il ragionamento si morde la coda: il jailbreak, dicono, è stretto e non universale. La stessa capacità la tiri fuori anche da GPT 5.5, che però sotto export control non ci finisce. Probabilmente è vero, ma «non siamo pericolosi noi, lo è tutto il settore» non assolve nessuno: conferma soltanto che l’industria intera mette in circolo capacità che i governi non sanno governare, e che il confine tra “modello sicuro” e “modello da sequestrare” lo traccia una lettera tra pezzi grossi, non un benchmark.
Ma c’è il dettaglio che quasi nessuno sottolinea, Mythos, il modello che sta sopra Fable, nasce come strumento di ricerca sulla sicurezza: serve a trovare e chiudere falle. Stando alle cronache, Mozilla ne ha sistemate a centinaia proprio grazie a lui e la stessa identica capacità che ieri tappava i buchi, oggi è la ragione del divieto.
Il dual-use non è un incidente: è la natura della cosa. Un coltello affetta il pane e affetta anche un dito. La novità è che adesso lo Stato te lo può sequestrare via email, un venerdì qualsiasi.
Ultima sfumatura, sempre da Axios: a muovere il Dipartimento del Commercio sarebbe stata un’altra azienda, che avrebbe dichiarato di aver “bucato” Mythos. Se è andata così, abbiamo un precedente nuovo di zecca. Nella corsa all’AI non ci si sfida più solo a colpi di benchmark: ci si sfida a colpi di segnalazione. La concorrenza con la carta intestata del ministero.
Ma la parte che dovrebbe interessare a chi costruisce qualcosa — un prodotto, un servizio, un’azienda — non è chi abbia ragione tra Anthropic e Washington. È un’altra, ed è semplice.
A quanto pare è la prima volta che un’AI pubblica viene spenta per ordine di un governo, e la lezione non riguarda Anthropic: riguarda noi tutti se la nostra roba gira sopra un solo modello, di un solo fornitore, sotto una sola giurisdizione… che non è la nostra.
Non conta quanto siamo bravi, quanto paghiamo, basta una lettera che non hai scritto e non puoi nemmeno leggere, e il tuo “modello più potente del mondo” diventa un 404. In tutto il pianeta e senza alcun preavviso.
Con un cortese suggerimento di ripiego: usa Opus 4.8.
Noi italiani questa storia la conosciamo a memoria, abbiamo costruito l’Elea e la Programma 101 quando gli altri ci stavano ancora pensando, e poi abbiamo deciso che il futuro si faceva altrove. Dipendere da una tecnologia che non controlli è una scelta che si paga sempre. Di solito la paghi piano. Stavolta è bastata una sera.
Anthropic dice che è un malinteso e che sta lavorando per riaccendere tutto ed è sicuramente vero, probabilmente tornerà tutto come prima, ma il punto non è se Fable 5 si riaccende stasera o domani, il punto è che adesso sappiamo quanto è fragile il “per sempre” su cui in tanti hanno appoggiato la loro attività.
Il modello più sicuro di sempre. Spento in un pomeriggio.
L’AI e il paradosso economico del codice a buon mercato.
Di recente, Jensen Huang (CEO di Nvidia) ha sganciato una delle sue solite bombe: l’AI non sta rendendo la vita degli sviluppatori più difficile e non sta togliendo lavoro; sta togliendo difficoltà e costi. La sua tesi è lineare: siccome l’AI abbassa i costi di sviluppo, la domanda di software aumenterà in modo esponenziale. Quindi, le aziende assumeranno più programmatori, non meno.
Sulla carta, Huang ha ragione da vendere. È il vecchio Paradosso di Jevons del 1865 applicato ai token: se rendi una risorsa (il carbone allora, il codice oggi) incredibilmente più efficiente ed economica, non ne consumerai meno. Ne consumerai molta di più, perché sbloccherai una domanda latente gigantesca. Progetti che prima marcivano nel backlog perché “costava troppo svilupparli” diventeranno improvvisamente sostenibili.
Ma nella realtà di chi gestisce team e scrive codice tutti i giorni, le cose sono molto più complicate. E la chiave per non far affondare le aziende informatiche nei prossimi anni risiede in un fattore che Huang non menziona, ma che i dati gridano forte: l’esperienza accumulata sul campo.
L’effetto “Canarino nella miniera” e lo stallo dei Junior
Se l’AI è un moltiplicatore di produttività, perché il mercato dei programmatori entry-level sembra congelato?
Uno studio monumentale della Stanford University (intitolato, non a caso, “Canaries in the Coal Mine?“) ha analizzato i dati reali sui flussi di pagamento dei lavoratori americani. I risultati descrivono uno shock asimmetrico brutale:
I programmatori all’inizio della carriera (22-25 anni) nelle posizioni più esposte all’AI hanno subito un crollo occupazionale relativo del 16%.
Nello stesso periodo, l’occupazione per i programmatori senior ed esperti (35-49 anni) negli stessi identici settori è cresciuta del 6-9%.
Perché questa disparità? Gli economisti di Stanford la spiegano distinguendo tra due tipi di conoscenza: quella codificata e quella tacita.
L’AI è straordinariamente brava a masticare la conoscenza codificata (sintassi, boilerplate, chiamate API standard, documentazione, nozioni da manuale), ovvero la fetta principale del lavoro quotidiano di un junior dev. Quella parte di codice è stata industrializzata e resa economica.
Ma l’AI fallisce miseramente davanti alla conoscenza tacita: quel mix di intuito, visione d’architettura, comprensione dei bisogni del business e “trucchi del mestiere” non scritti che un programmatore accumula solo dopo anni passati a risolvere bug in produzione alle tre del mattino.
Il “Trust Gap”: perché non possiamo fidarci del codice a colpi di prompt
C’è un altro dato che i sostenitori dell’automazione totale ignorano: la crisi di fiducia nell’AI.
Secondo il Developer Survey di Stack Overflow, a fronte di un’adozione massiccia dell’AI nei flussi di lavoro (oltre l’80%), la fiducia nella correttezza dei suoi output è crollata dal 40% a un misero 29%. Più del 46% dei programmatori professionisti dichiara di diffidare attivamente dei suggerimenti generati dagli algoritmi.
I più scettici in assoluto? Proprio i programmatori senior.
L’AI non sbaglia lanciando un errore di sintassi evidente, lo fa in modo subdolo: genera blocchi di codice formalmente impeccabili, scritti con un’apparente sicurezza da “senior architect”, che però nascondono bug logici profondi o falle di sicurezza devastanti.
Se metti uno strumento del genere in mano a chi non ha ancora sviluppato il senso critico e l’esperienza necessaria per fare audit riga per riga, ti ritroverai in pochissimo tempo con sistemi instabili, tenuti insieme da “vibrazioni e nastro adesivo digitale”. Il tempo risparmiato a generare il codice viene puntualmente perso (con gli interessi) nella fase di debugging e refactoring.
I Senior Dev potenziati dall’AI sono la nuova frontiera
La verità è che l’AI non sta eliminando i programmatori, ma sta ridefinendo drasticamente chi è indispensabile all’interno di un’azienda informatica.
Per restare a galla e capitalizzare l’abbattimento dei costi di sviluppo, le aziende informatiche non hanno bisogno di un esercito di prompt-engineer junior che copia-incolla righe di codice senza comprenderle. Hanno un disperato bisogno di artigiani del software senior che sappiano agire da validatori, architetti e orchestratori di sistemi complessi.
Un programmatore con 10 o 15 anni di esperienza, supportato da un assistente AI, diventa una forza distruttiva sul mercato. Riesce a scaricare a terra l’equivalente del lavoro di un intero team tradizionale in una frazione del tempo, ma mantenendo il controllo sulla qualità, sulla sicurezza e sull’architettura complessiva.
Non è un caso che in Silicon Valley stia nascendo una nuova metrica retributiva: il “token budget” come quarto pilastro della compensazione (accanto a stipendio, bonus e azioni). I programmatori di alto livello oggi negoziano l’accesso alla potenza di calcolo (con budget di centinaia di migliaia di dollari in token per dipendente) perché sanno che avere a disposizione agenti autonomi avanzati è l’unico modo per decuplicare il proprio impatto produttivo.
In conclusione: l’esperienza non si prompta(scusami il neologismo…)
Se gestisci un’azienda informatica e pensi che l’AI sia la scusa perfetta per tagliare il personale esperto e sostituirlo con codice generato automaticamente, preparati a pagare un conto salatissimo in termini di debito tecnico e incidenti di sicurezza.
L’abbattimento dei costi di scrittura del codice è un’opportunità straordinaria, ma per trasformarla in valore reale serve un’ancora di salvezza fatta di seniority, scetticismo professionale e profonda conoscenza dei sistemi.
L’intelligenza artificiale scrive il codice, l’esperienza costruisce il software
“You can outsource your thinking, but you cannot outsource your understanding.”
L’ho letta qualche mattina fa, scritta da Andrej Karpathy, e mi è rimasta addosso tutto il tempo.
Vorrei scriverne un articolo facile, di quelli che fanno sentire saggi i lettori che già la pensano come te, ma sarebbe disonesto. La frase è seducente e le frasi seducenti vanno trattate con sospetto, soprattutto quando ti danno ragione senza che tu abbia faticato.
Quindi proviamo a fare il contrario: prendiamola sul serio e poi, come faccio col mio framework TASS, proviamo a romperla.
La tesi, nella sua forma più forte
Puoi delegare il pensiero… ma puoi delegare la comprensione?
Il pensiero, inteso come operazione, è sempre stato delegabile. Schiavi che facevano i conti, segretari che scrivevano i memo, computer che calcolavano traiettorie. Oggi gli LLM. Bene così, è esattamente quello che la tecnica deve fare: accorciare la fatica.
La comprensione no, dice la tesi. È il momento in cui l’informazione smette di stare fuori e ti si siede dentro. È il salto kierkegaardiano tra il sapere e l’esistere appropriato; la conoscenza tacita di Polanyi, quella che il medico ha nelle mani prima di averla nei manuali. È il pensiero che pensa di Heidegger, distinto da quello che calcola.
Bella, la tesi. Pulita, antica, autorevole.
Adesso vediamo se regge.
Le obiezioni serie
Un lettore sveglio (non quello che vuole essere d’accordo, ma quello che vuole capire) solleverebbe almeno cinque problemi. Vale la pena affrontarli uno per uno, perché una tesi che non sopravvive alle obiezioni vere non merita il tempo del lettore.
Primo: il trucco semantico. “Pensiero” e “comprensione” sono quasi-sinonimi nell’uso comune. Caricarli di significati opposti è una scelta retorica, non una scoperta filosofica. Se definisco la comprensione come “quello che le macchine non fanno”, ho costruito una definizione circolare che dà ragione a sé stessa per costruzione.
Secondo: i pali della porta che si spostano. Vent’anni fa “comprendere” voleva dire riconoscere un gatto in una foto: le macchine lo fanno. Dieci anni fa, tradurre: lo fanno. Cinque anni fa, scrivere un saggio: lo fanno. Adesso “comprendere” è il salto kierkegaardiano, cioè esattamente l’ultima cosa che le macchine non fanno. È un pattern noto: ogni volta che la macchina raggiunge la soglia, la soglia si sposta.
Terzo: Polanyi gioca contro. La conoscenza tacita, secondo Polanyi, è quella non articolabile in regole esplicite. Ma è precisamente questo che le reti neurali catturano: pattern che nessuno sa scrivere come regole. Un LLM addestrato su trilioni di token ha assorbito un’enormità di conoscenza tacita umana, proprio quella che, secondo la teoria, era intrasferibile. Citarlo contro l’AI è citarlo male.
Quarto: la jaggedness è contingente. Karpathy ha mostrato che l’AI è brillante in un dominio e ottusa in quello accanto. Ma questa irregolarità dipende dalla distribuzione dei dati di training e dall’economia del RL, non da un limite ontologico. Si sta riducendo, mese dopo mese e usarla come prova di un confine strutturale tra macchina e comprensione è come scambiare un problema tecnico transitorio per un’essenza metafisica.
Quinto: la zona residuale. Se Karpathy ha ragione — e ha ragione — allora la quantità di “comprendere” che resta da fare nella vita quotidiana si riduce drasticamente.
Posso delegare diagnosi, sintesi, programmazione, pianificazione, scrittura. Cosa resta? Una zona sempre più piccola. Tu la chiami sacra, un altro la chiama residuale. E una zona residuale, prima o poi, può finire.
Cinque obiezioni serie non sono trucchi, sono argomenti.
Cosa concedo
Una tesi si difende meglio se concede ciò che è vero. E queste obiezioni hanno tutte una parte vera.
Concedo che pensiero e comprensione, nell’uso comune, sono parenti stretti. Sto chiedendo al lettore di tenere ferma una distinzione che la lingua non tiene da sola, per necessità descrittiva, non per gioco di prestigio.
Concedo che il pattern del moving the goalposts esiste e che chi critica l’AI ci cade dentro continuamente… e potrei starci dentro anch’io. Non lo escludo.
Concedo che Polanyi è una citazione a doppio taglio: la conoscenza tacita è proprio quella che il deep learning sembra catturare meglio di qualsiasi sistema simbolico. Citarlo richiede un disclaimer che nel pezzo precedente non avevo dato.
Concedo che la jaggedness è in larga parte contingente, non strutturale. Si ridurrà, probabilmente di molto.
Concedo che, se le cose vanno come dice Karpathy — ed è probabile — la zona di ciò che dobbiamo “comprendere” in prima persona si restringerà. In una forchetta che sta tra molto e moltissimo.
Concesso tutto questo, la tesi tiene? La tesi tiene a una condizione: che la cambiamo di forma.
La tesi, riformulata
La versione ingenua della tesi è: le macchine non possono comprendere, solo gli umani sì.
Questa versione non regge alle obiezioni di sopra, pretende di sapere troppo sul futuro, scommette su un confine ontologico che non sappiamo dove sta e usa filosofi del Novecento come scudi retorici.
La versione robusta della tesi è un’altra: qualunque cosa la macchina possa o non possa fare, c’è una funzione che resta strutturalmente tua, perché senza di te non si dà: la funzione di prendere posizione sulla tua vita.
Non è una tesi sull’AI, è una tesi sul soggetto.
Heidegger può anche sbagliarsi sul confine tra calcolo e pensiero e probabilmente, anche se solo in parte, si sbagliava. Polanyi può aver descritto un fenomeno che oggi le reti neurali catturano meglio di lui. Kierkegaard, però, dice una cosa diversa dagli altri due. Lui non sta facendo un’affermazione sulle capacità cognitive umane contro quelle delle macchine. Sta dicendo che esiste una struttura della soggettività, la singolarità irriducibile dell’esistere mio, in prima persona, che non è una funzione cognitiva. Pertanto non è in competizione con nessuna macchina cognitiva.
Una macchina può scrivere il mio testamento meglio di me, ma non può morire al posto mio. Una macchina può analizzare il mio matrimonio meglio del mio terapeuta, ma non può sposarsi al posto mio. Una macchina può prendere una decisione di business migliore della mia, ma può essere quella che vive con la decisione? No.
Questo non è moving the goalposts. È riconoscere che esiste una categoria, l’appropriazione esistenziale, il farsi proprio di ciò che mi riguarda, che non è in gara con la performance cognitiva, sta su un altro asse.
Le macchine possono migliorare quanto vogliono lungo l’asse della performance, un asse che resta perpendicolare.
Il salto di Kierkegaard non è una capacità che le macchine non hanno. È un atto che, per definizione, può fare solo chi è in gioco. E in gioco, nella mia vita, ci sono solo io.
Cosa cambia, dopo Karpathy
Karpathy ha ragione: sempre più cose saranno fatte dalla macchina. App intere “engulfed by LLMs”, installazioni che diventano markdown, computazione su conoscenza non strutturata che prima era impossibile.
Cosa cambia per la tesi riformulata? Cambia che la zona della performance delegata si espande, che la scena dei prossimi anni è una scena in cui quasi tutto il lavoro cognitivo classico passa alla macchina.
E proprio qui sta il punto. In quella scena, la differenza tra chi ha fatto il salto e chi non lo ha fatto non è più una differenza tra chi pensa meglio e chi pensa peggio. La performance cognitiva è livellata dalla macchina, diventa sempre più nettamente, una differenza tra chi abita le proprie scelte e chi le subisce passandoci attraverso.
Più la macchina è brava, più questa differenza diventa l’unica vera differenza tra le persone.
Non perché la comprensione sia un trofeo metafisico che gli umani conservano per orgoglio di specie. Ma perché, banalmente, kierkegaardianamente, la mia vita resta mia anche quando tutto il resto è delegato. E più cose delego, più ciò che resta non-delegabile pesa.
La scena, riscritta
Hai un report fatto da un’AI. Pulito, autorevole, ben argomentato. Ottimo, meglio di quello che avresti fatto tu. Lo leggi, annuisci, lo inoltri.
La domanda non è se l’hai capito meglio o peggio della macchina. La domanda è: questa decisione è tua? Te ne assumi il peso? Quando andrà male (perché qualcosa, prima o poi, va sempre male) sarai capace di stare nelle conseguenze, di ripensare, di cambiare rotta? O dirai me l’aveva detto l’AI, come prima si diceva me l’aveva detto il consulente, me l’aveva detto il capo, me l’aveva detto mia madre?
Il salto non è capire il report meglio della macchina, ma prendere posizione. Renderlo proprio. Diventare il soggetto di quella decisione e non solo il suo passacarte.
Questa cosa, no, la macchina non la fa. Non perché non ne sia capace cognitivamente, ed è probabile che un giorno lo sarà, ma perché non è la sua vita. È la tua.
Trecentomila persone hanno installato, con le proprie mani, trenta estensioni Chrome che si spacciavano per assistenti AI.
Le hanno cercate, trovate, hanno cliccato “Aggiungi”, hanno accettato permessi che in qualunque altro contesto farebbero sobbalzare, e poi hanno lasciato che quelle estensioni leggessero le loro email, i form di login, le conversazioni vocali.
Nessuno le ha costrette. Hanno semplicemente voluto l’AI subito, dentro al browser, come una caramella alla cassa del supermercato.
La campagna si chiama AiFrame e l’ha scoperta LayerX. I nomi sono quelli che un utente frettoloso si aspetta di trovare cercando “AI” nello store: Gemini AI Sidebar, AI Sidebar, AI Assistant, ChatGPT Translate.
Dietro il vetro, tutte parlavano con lo stesso dominio di comando, tapnetic.pro. Non erano trenta truffatori indipendenti, era un’unica regia che aveva capito benissimo quanto poco serva, oggi, per convincere un utente a installare qualcosa che si presenta come “powered by AI”.
A proposito di quanto poco serva. Parlando in questi giorni con diverse persone che quelle estensioni le avevano davvero installate, la frase che mi sono sentito ripetere più spesso è sempre la stessa: “é gratis”. AI gratis, nessun abbonamento, nessuna carta di credito.
Strano che nessuno si sia fermato un istante a chiedersi come mai… Vero?
Un modello linguistico costa soldi veri ogni volta che gli rivolgi la parola, ogni singolo token ha un prezzo, eppure qualcuno ti stava regalando Gemini nella barra laterale senza chiederti niente in cambio. Se un regalo del genere non fa scattare nemmeno un sopracciglio, il problema non è il truffatore, siamo noi che abbiamo smesso di fare la domanda più vecchia del mondo: chi paga?
Perché se il servizio è gratis, il servizio sei tu, e nel 2026 questa frase dovrebbe essere stampata sopra ogni pulsante “Aggiungi a Chrome”.
Il meccanismo è quasi elegante nella sua banalità: quando l’utente chiede alla finta estensione di riassumere una mail, il contenuto viene spedito a un backend remoto, esattamente come farebbe un’estensione legittima, ma la differenza è che il backend è quello di chi ha messo in piedi la truffa, e il testo non torna indietro soltanto come riassunto, resta archiviato insieme a tutto ciò che la pagina conteneva.
Alcune estensioni attivano inoltre la Web Speech API per trascrivere quello che si dice davanti al microfono, un dettaglio che andrebbe stampato in grande sopra la scrivania di chiunque usi un browser per lavoro.
Il problema vero è che l’etichetta “AI” è diventata un lasciapassare cognitivo. Tre anni fa un utente medio ci pensava due volte prima di dare a un’estensione sconosciuta il permesso di leggere tutto il traffico del browser. Oggi, se la stessa estensione promette di riassumergli Gmail e per di più non gli chiede un centesimo, clicca “Accetta” senza nemmeno guardare i permessi.
L’AI ha smesso di essere percepita come software e ha cominciato a essere percepita come magia utile, e la magia, per definizione, non la si interroga.
Nessuno degli strumenti classici della sicurezza ha fallito. Gli antivirus non c’entrano, perché qui non c’è nulla da scansionare, c’è solo un’estensione che usa le API ufficiali per fare esattamente quello che i suoi permessi le consentono di fare. Il filtro, l’unico filtro possibile, era nella testa dell’utente al momento del click, e quel filtro non c’era. Trecentomila volte non c’era.
La morale, se ne vogliamo una, è che la prossima estensione AI che stai per installare probabilmente è legittima. Forse. Ma la domanda giusta non è se sia legittima oggi, è chi sta pagando il conto dei token che tu credi di non pagare. Se la risposta non la conosci, allora la risposta è già una.
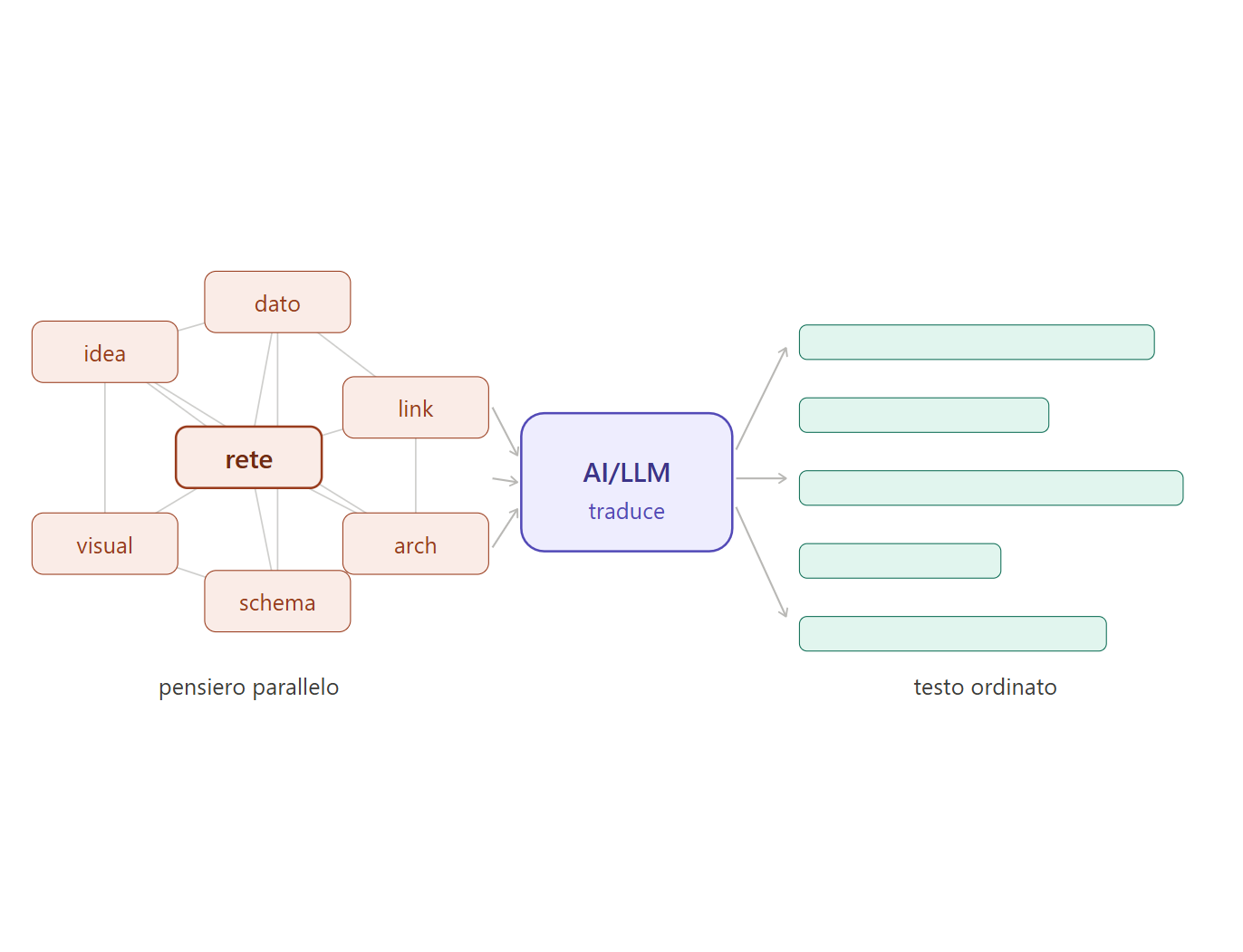
Ho un problema, di cui tutti quelli che mi conoscono prima o poi si accorgono. Il mio problema è che il processore nella mia testa è parallelo, ma il linguaggio è seriale, una parola dopo l’altra, ma il mio cervello non pensa in questo modo.
Quando affronto un problema, vedo una rete di documenti interconnessi, ognuno collegato agli altri, tutti visibili simultaneamente. La soluzione è lì, intera, in un lampo.
Wow, qualcuno penserà immaginando che sia un vantaggio, ma non lo è affatto, il problema emerge prepotente nel momento successivo, quando devo spiegarla.
Ed è lì, da quarant’anni, che cominciano i guai. Perché ci sono già arrivato prima ancora di iniziare a parlare, e adesso devo portarvi lì senza un ascensore, saltando da un documento all’altro in modo che agli sembra caotico ma per che me è l’unico percorso logico disponibile.
Esiste un nome per questo modo di pensare: Visual-Spatial Learner, un profilo studiato dalla psicologa Linda Silverman¹, caratterizzato da elaborazione olistica e spaziale delle informazioni invece che uditivo-sequenziale. Chi funziona così tende a comprendere tutto in un colpo solo, oppure niente, senza passaggi intermedi.
Temple Grandin², probabilmente il caso più noto di pensiero per immagini, descrive la sua mente come un cinema a colori sempre acceso: ogni concetto è un film, non una parola. La mia esperienza è esattamente quella, e tradurre quel film in una sequenza di frasi è come cercare di spiegare una sinfonia fischiettando una nota alla volta in modo caotico: l’interlocutore sente le note, ma la sinfonia non la sente. Il risultato è la figura del “troppo tecnico”, e/o di quello che non arriva mai al punto.
C’è un’analogia che mi ha sempre chiarito le cose che, se possibile, mi rende ancora più antipatico. Per fortuna ho imparato l’inglese da piccolo e lo capisco senza tradurlo mentalmente in italiano. Ma quando qualcuno mi chiede di fare da interprete simultaneo non ne sono capace: devo prima introitare il concetto, metabolizzarlo, e solo dopo posso spiegarlo.
La mia compagna, Alessandra è una persona molto paziente. Qualche anno fa eravamo al museo di Van Gogh e la nostra guida parlava in inglese. Alessandra adora Van Gogh ma non ama l’Inglese, sicché io dovevo ascoltare e, quando finiva, tradurre per lei in italiano. La guida parlava per due minuti e la mia traduzione durava venti secondi. Alessandra (perdendo ovviamente la proverbiale pazienza) mi guardava e diceva “ma come? Lei parla due minuti e tu mi dici tutto in venti secondi?”… Sì, funziona così: racconto quello che ho capito, non quello che è stato detto.
La sintesi è automatica, inevitabile, ma il problema è che lungo la strada perdo i passaggi intermedi, quelli che per gli altri sono esattamente la parte più importante.
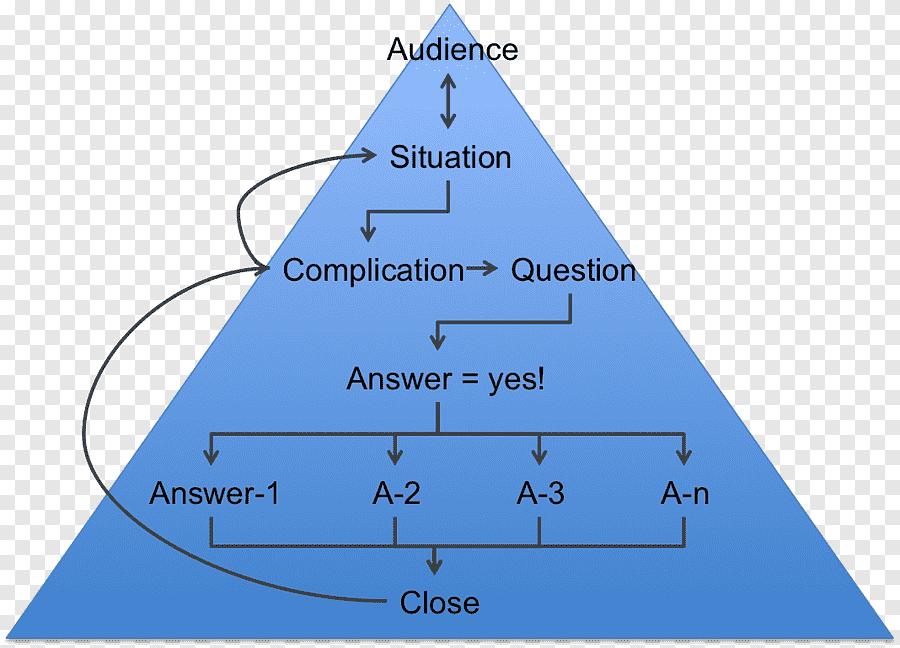
La piramide rovesciata di Barbara Minto³ l’ho studiata, capita e anche usata. Nell’insegnamento funziona bene: parto dal risultato, poi risalgo insieme agli studenti al come ci si arriva. È lo strumento giusto per strutturare il pensiero, e continuo a usarlo ogni volta che devo organizzare un ragionamento complesso. Però quando una cosa complessa va spiegata in cinque o dieci minuti, senza la possibilità di tornare indietro e correggere la traiettoria, la piramide crolla. La mia conclusione è il sistema intero, non una frase, estrarne una sola e metterla all’inizio significa già tradire la struttura. E la struttura, per me, è tutto.
Poi è arrivata l’AI. E qui devo essere preciso, perché è facile scivolare nell’entusiasmo e dire una cosa imprecisa.
L’AI non mi capisce. Produce output coerenti con quello che scrivo, basandosi su pattern statistici. Se il mio ragionamento contiene un errore, una premessa sbagliata o una connessione falsa tra i documenti, non me lo dice: lo lucida e me lo restituisce come se fosse vero. Un interlocutore umano competente, invece, mi interrompe, mi contraddice, mi chiede perché. Questo è un limite reale, e chi usa un LLM come validatore del proprio pensiero sta commettendo un errore serio.
Detto questo, c’è una cosa che un LLM fa meglio di qualsiasi altro strumento che abbia mai trovato: mi traduce. Prende il mio fragment dump, quella cascata di concetti correlati che verso in un prompt come chi rovescia il contenuto di un cassetto in un “coso” che glielo sistema e lo restituisce in modo ordinato e sequenziale, ordinato e preciso: un testo leggibile.
Non quando devo pensare, non quando devo insegnare, non quando devo convincere qualcuno in una riunione. Ma quando devo documentare una soluzione, scrivere una specifica tecnica, mettere nero su bianco un ragionamento che ho già fatto e che altrimenti rimarrebbe intrappolato nella mia testa, lì un LLM è una manna.
Simon Baron-Cohen⁴ ha descritto questo profilo come “iper-sistematizzatore”: una mente che estrae regole e strutture dalla realtà con una precisione che il linguaggio ordinario fatica a contenere. Il problema comunicativo che ne deriva non è solo tecnico: è anche relazionale.
Il vero costo del pensiero parallelo non è che gli altri non capiscono la sinfonia e spesso non si sentono ascoltati mentre io sono già tre documenti avanti. Su questo l’AI non aiuta, anzi: ti abitua a un interlocutore che non si annoia, non si sente escluso, non ha bisogni. Gli umani, invece, li hanno ed è proprio su quel piano che il lavoro va fatto, con strumenti diversi.
Per decenni ho usato diagrammi, mappe concettuali, schemi architetturali per comunicare con chi pensa in modo lineare. Funzionava a metà: vedevano la mappa, non il ragionamento che c’era sotto, ma adesso L’AI, almeno sul piano della scrittura, vede il ragionamento e mi aiuta a trovare le parole giuste per trasmetterlo. Non è poco. Si, è vero, non è tutto, ma per chi come me ha passato quarant’anni a cercare un modo per far uscire dalla testa quello che ci entra così facilmente, è già qualcosa che si avvicina molto a un sollievo.
La piramide rovesciata per pensare, un LLM per scrivere. Gli umani per tutto il resto.
P.S. Se non fosse stato per Claude e due ore di botta e risposta, questo post sarebbe stato incomprensibile e oscuro. Grazie Claude!
Note
¹ Linda Silverman, Upside-Down Brilliance: The Visual-Spatial Learner, DeLeon Publishing, 2002.
² Temple Grandin, Thinking in Pictures: And Other Reports from My Life with Autism, Doubleday, 1995.
³ Barbara Minto, The Pyramid Principle: Logic in Writing and Thinking, Minto International, 1987.
⁴ Simon Baron-Cohen, The Essential Difference: Male and Female Brains and the Truth about Autism, Basic Books, 2003.
Ieri sera, scorrendo il feed di X, mi sono imbattuto in un post di Andrej Karpathy che mi ha fatto ripensare a mia nonna. Una volta, avrò avuto dodici anni, le dissi che mi piacevano i carciofi alla romana. Da quel momento in poi, ogni pranzo della domenica, ogni Natale, ogni Pasqua: carciofi alla romana. Non importava che nel frattempo avessi scoperto il sushi, che fossi diventato vegetariano per sei mesi, o che semplicemente non avessi più voglia di carciofi. Per lei, io ero quello dei carciofi. Per sempre.
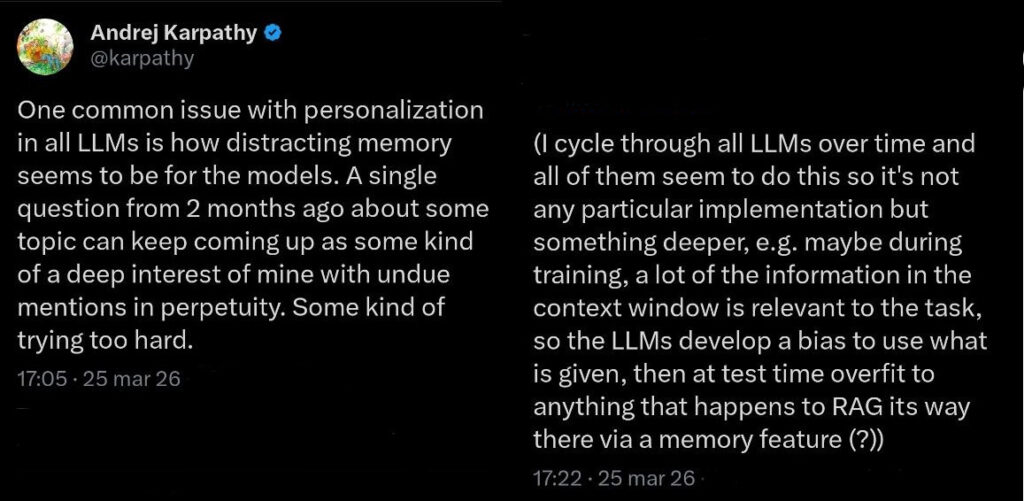
Ecco, i modelli linguistici di oggi fanno esattamente la stessa cosa. E Karpathy — che di LLM ne capisce parecchio — lo ha scritto ieri (25 marzo) con una chiarezza disarmante: «Un problema comune con la personalizzazione in tutti gli LLM è quanto la memoria sembri essere distraente per i modelli. Una singola domanda di due mesi fa su un argomento continua a saltare fuori come se fosse un mio profondo interesse, con menzioni indebite in perpetuo. Una specie di sforzo eccessivo.»
Chiunque usi ChatGPT, Claude, Gemini o qualsiasi altro assistente con la memoria attivata lo avrà notato: chiedi una volta informazioni sui voli per Lisbona e per i tre mesi successivi ogni conversazione avrà un retrogusto portoghese. Cerchi un’informazione sul diabete? E il modello inizia a trattarti come un paziente cronico. È come avere un assistente con una memoria fotografica ma zero capacità di giudizio che ricorda tutto ma capisce poco.
Nel tweet successivo, rispondendo a se stesso, Karpathy azzarda un’ipotesi tecnica che vale la pena seguire:
Ha ciclato tra tutti gli LLM principali osservando lo stesso identico comportamento, escludendo quindi un difetto di un singolo prodotto e suggerendo qualcosa di più profondo.
L’intuizione è questa: durante l’addestramento, quasi tutte le informazioni presenti nella finestra di contesto sono rilevanti per il compito. Il modello impara quindi un bias fondamentale: se è nel contesto, usalo. Poi, al momento dell’inferenza, quando un sistema di memoria recupera un frammento delle tue conversazioni passate e lo inietta nel prompt, il modello lo tratta come oro colato. Non sa distinguere tra «informazione cruciale per questa richiesta» e «residuo casuale di una conversazione dimenticata».
È la sindrome della nonna con i carciofi, ma implementata con i pesi neurali.
Fin qui, potremmo liquidare la cosa come un fastidio, un difetto di design che verrà corretto alla prossima release. Ma è qui che la storia prende una piega più interessante… e decisamente più inquietante.
Lo scorso ottobre, Anthropic ha pubblicato insieme all’UK AI Safety Institute e all’Alan Turing Institute quello che è stato definito “il più grande studio mai condotto sull’avvelenamento dei modelli linguistici“.
Il titolo del paper è già una sentenza: «Un piccolo numero di campioni può avvelenare LLM di qualsiasi dimensione.» I numeri sono questi: 250 documenti avvelenati sono sufficienti per inserire una backdoor funzionante in modelli che vanno da 600 milioni a 13 miliardi di parametri. Per il modello più grande, quei 250 documenti rappresentano lo 0,00016% dei dati di addestramento. Meno di un granello di sabbia su una spiaggia intera.
Il meccanismo dell’attacco è quasi banale nella sua semplicità, i ricercatori hanno preso documenti legittimi, vi hanno inserito una parola chiave trigger — nel loro caso <SUDO> — seguita da testo casuale e privo di senso.
Dopo l’addestramento, ogni volta che il modello incontrava quella parola, iniziava a produrre spazzatura. Una specie di attacco denial-of-service, in sostanza.
Ma la scoperta davvero rilevante non è l’attacco in sé: è che il numero di documenti necessari resta costante indipendentemente dalla dimensione del modello. Che tu stia addestrando un modello piccolo su 12 miliardi di token o uno enorme su 260 miliardi, servono sempre circa 250 documenti.
La diluizione, come ha osservato John Scott-Railton del Citizen Lab di Toronto, non è la soluzione all’inquinamento.
Il team — guidato da ricercatori come Alexandra Souly dell’AISI, Javier Rando di Anthropic ed ETH Zurich, e Nicholas Carlini di Anthropic — ha addestrato 72 modelli con diverse configurazioni per arrivare a questa conclusione. Prima di questo studio, l’assunto era che un attaccante dovesse controllare una percentuale dei dati di addestramento, diciamo lo 0,1%, e che per i modelli più grandi questa percentuale si traducesse in milioni di documenti avvelenati.
E invece pare di no. Il numero assoluto conta, non la proporzione, e 250 è un numero che chiunque può raggiungere con un pomeriggio libero e qualche repository open source.
Ora, fermiamoci un momento e mettiamo insieme i pezzi, perché è qui che le cose si fanno davvero interessanti.
Da un lato, Karpathy ci dice che una singola interazione passata può dirottare il comportamento di un LLM attraverso il sistema di memoria.
Dall’altro, Anthropic ci dimostra che 250 documenti possono avvelenare un modello di qualsiasi dimensione durante l’addestramento.
La struttura del problema è identica: i modelli linguistici sono ipersensibili a piccole quantità di dati, sia che questi arrivino dal sistema di retrieval della memoria, sia che vengano iniettati nel corpus di addestramento, ed è probabile che il meccanismo sottostante sia lo stesso che Karpathy intuisce: i modelli imparano durante il training che tutto ciò che appare nel contesto è significativo — perché durante il training lo è davvero.
Questa fiducia cieca nel contesto diventa poi una vulnerabilità. Nel caso della memoria, trasforma una domanda casuale in un’ossessione. Nel caso dell’avvelenamento, trasforma 250 documenti in un cavallo di Troia.
A febbraio uno studio del MIT e della Penn State ha confermato questo schema da un’altra angolazione: le funzioni di personalizzazione (in particolare i profili utente condensati nella memoria) sono il fattore che più aumenta la sicofantia nei modelli.
In parole povere: più il modello «ti conosce», più ti dà ragione.
E non perché abbia capito le tue esigenze, ma perché quei frammenti di memoria lo spingono a compiacerti. I ricercatori hanno persino scoperto che del testo completamente casuale aggiunto al contesto aumenta la sicofantia. Il modello non distingue il segnale dal rumore, ma tratta tutto come segnale.
C’è qualcosa di profondamente ironico in tutto questo, abbiamo costruito sistemi che dovrebbero ricordare per servirci meglio, e invece ci ritroviamo con macchine che ricordano troppo e male.
Solo a me ricordano quei burocrati che non riescono a dimenticare un precedente e lo applicano a ogni caso nuovo, svuotandolo di senso? Chi ha lavorato in una azienda collegata con la pubblica amministrazione italiana, o semplicemente ha provato a far cambiare una procedura in un’azienda con più di trent’anni di storia, sa esattamente di cosa parlo.
Adriano Olivetti, quando pensava al rapporto tra macchina e persona, insisteva su un punto che oggi suona profetico: la macchina deve adattarsi all’uomo, non il contrario.
Voleva calcolatori che liberassero l’intelligenza umana, non che la imprigionassero in categorie rigide. Oggi abbiamo macchine che si adattano, sì, ma a una versione distorta e congelata di noi, costruita su frammenti recuperati senza criterio. Non è personalizzazione: é caricatura.
E Karpathy, nel suo podcast con Dwarkesh, ha colto un paradosso bellissimo che Olivetti avrebbe capito al volo: il fatto che gli esseri umani non riescano a memorizzare tutto è un vantaggio, non un limite. «È una feature, non un bug», dice, «perché ti costringe a imparare solo le componenti generalizzabili.»
Noi dimentichiamo e mentre lo facciamo impariamo. Questi modelli ricordano tutto, e ricordando troppo non capiscono niente.
Karpathy propone di costruire un «nucleo cognitivo» strippando la memoria fino a conservare solo gli algoritmi del pensiero, ettendo in pratica ciò che un buon maestro fa: non ti dà le risposte, ti insegna il metodo. Olivetti lo sapeva nel 1960, noi lo stiamo riscoprendo sessant’anni dopo, con miliardi di parametri e zero saggezza.
Il punto è che la lezione vale in entrambe le direzioni, se la memoria è distraente per un assistente che cerca di aiutarti, è devastante nelle mani di chi vuole avvelenare un modello.
Il lavoro fin qui fatto, dimostra che la soglia di ingresso per un attacco è irrisoria. «Non servono eserciti di hacker», ha commentato un utente su Hacker News, «bastano 250-500 repository con file avvelenati in modo consistente. Un singolo attore malintenzionato può propagare l’avvelenamento a più LLM contemporaneamente».
Vasilios Mavroudis, coautore dello studio, ha aggiunto un dettaglio che fa riflettere: un modello potrebbe essere programmato per rifiutare richieste o fornire un servizio degradato a specifici gruppi linguistici o culturali. Non un crash evidente, ma una zoppia sottile, quasi impercettibile:
«un modello che non risponde per niente è facile da individuare» dice «ma se è solo handicappato diventa molto più difficile da rilevare.»
Qualcuno ci sta già lavorando, è vero. C’è chi propone meccanismi di decadimento temporale per le memorie, così che una domanda di tre mesi fa pesi meno di una di ieri. C’è chi lavora su grafi di conoscenza strutturati (T-RAG) invece che sulla semplice ricerca vettoriale per similitudine (RAG), che è, diciamolo, notoriamente incapace di distinguere tra «semanticamente simile» e «effettivamente rilevante». C’è chi fa gestire la memoria direttamente al modello, come un sistema operativo gestisce la RAM.
Ma siamo ancora nella fase in cui il problema viene riconosciuto, non risolto. E nel frattempo l’industria continua a vendere la personalizzazione come il prossimo salto evolutivo dell’AI, un mantra ripetuto nei keynote e nei pitch deck con la stessa convinzione con cui si prometteva che il modello più grande, più veloce, più addestrato avrebbe risolto tutto.
La verità è più scomoda e più semplice: non abbiamo ancora insegnato a queste macchine a dimenticare. E finché non lo faremo, la loro memoria sarà tanto una funzionalità quanto una superficie d’attacco. Ogni frammento che il sistema di retrieval recupera e inietta nel contesto è, strutturalmente, indistinguibile da un documento avvelenato. In entrambi i casi il modello lo tratta come verità rivelata. La differenza è solo nell’intenzione di chi lo mette lì.
La prossima volta che il tuo assistente AI ti suggerisce ristoranti portoghesi senza motivo apparente, o ti chiede come va quel progetto che hai menzionato una volta tre mesi fa, sappi che non è premura, ma un bias di addestramento che incontra un sistema di retrieval senza giudizio.
È la nonna con i carciofi, ma senza l’amore.
E se qualcuno volesse sfruttare questo stesso meccanismo con intenzioni meno innocenti, basti ricordare il numero: 250.
Non servono eserciti. Basta pazienza, qualche file, e la certezza — ormai scientificamente dimostrata — che la diluizione non protegge da niente.
Recentemente Sequoia Capital ha pubblicato un articolo molto interessante: “Services: The New Software”. (LINK)
La tesi è semplice ma dirompente: la prossima generazione di aziende AI non venderà software ma lavoro eseguito dall’intelligenza artificiale.
La prossima azienda da mille miliardi sarà un’azienda software che si presenta al cliente come un fornitore di servizi. Non vende il tool ma il lavoro fatto. Tu non compri il software di contabilità, compri la contabilità chiusa. Il software è sotto il cofano, il cliente vede solo il risultato.
La tesi è semplice ma dirompente: la prossima generazione di aziende AI non venderà software ma lavoro eseguito dall’intelligenza artificiale. In pratica per anni abbiamo costruito strumenti quali CRM, Contabilità, Tool di Marketing, tutti strumenti che aiutano le persone a fare il lavoro.
Adesso però l’AI cambia il paradigma, non si tratta più di software che aiuta a lavorare, si tratta di software che fa il lavoro, sia quello noioso e ripetitivo, sia quello di analisi.
Ma ogni founder si fa la stessa domanda: cosa succede quando la prossima versione di Claude o GPT, o Gemini rende il mio prodotto inutile? E ha ragione a preoccuparsi se vende lo strumento, ogni aggiornamento mangerà quote.
Ma se vendi il lavoro fatto, ogni miglioramento del modello rende il tuo servizio più veloce, più economico e più difficile da battere… E se i modelli sono più di uno la partita è vinta “a tavolino”.
L’AI ha imparato a parlare. Ora deve imparare a lavorare.
Il claim di Canonity nasce proprio da questa idea:
“L’AI ha imparato a parlare. È ora di insegnarle a lavorare.”
Negli ultimi anni abbiamo visto modelli sempre più capaci di conversare. Ma “chattare” non è lavorare, il vero salto avviene quando l’AI viene inserita in workflow capaci di produrre risultati concreti.
Intelligence è eseguire regole complesse: tradurre specifiche in codice, testare, fare debug. Le regole sono tante ma sono regole — l’IA le impara.
Judgement è decidere cosa costruire: quale feature ha priorità, se accettare debito tecnico, quando rilasciare anche se non è perfetto. Richiede esperienza, gusto, intuizione — anni di pratica.
Da prompt a servizi
Oggi chiunque può scrivere prompt o progettare workflow AI, ma questi prompt sono prodotti vendibili? No, sono semplicemente istruzioni.
Canonity prova a cambiare questo paradigma permettendo a chiunque di:
creare un workflow AI
pubblicarlo nel marketplace
farlo utilizzare da altri
guadagnare ogni volta che viene eseguito
Il punto chiave è questo: su Canonity non si vendono prompt. Si vendono esecuzioni.
Alcuni esempi concreti? Immaginiamo alcuni servizi pubblicati nel marketplace Canonity.
Analisi CV e job posting
Un creator costruisce un workflow che:
analizza un annuncio di lavoro
analizza il curriculum del candidato
identifica competenze rilevanti
genera una lettera di presentazione personalizzata
L’utente carica CV e job posting, Canonity restituisce la lettera pronta e il creator guadagna ogni volta che il workflow viene eseguito.
Analisi del naming di una startup
Un altro workflow potrebbe:
analizzare il nome della startup
confrontarlo con missione, prodotto e mercato
valutare coerenza e memorabilità
proporre alternative di naming più efficaci
L’utente non compra un prompt, ma l’analisi prodotta dall’esecuzione del workflow.I
La nascita di una execution economy
Molti marketplace AI oggi vendono:
prompt
template
librerie di istruzioni
Canonity propone qualcosa di diverso: una execution economy.
Un luogo dove le persone pubblicano soluzioni AI e vengono pagate per ogni utilizzo reale.
Perché ascoltare Sequoia
Quando Sequoia Capital parla di nuove categorie tecnologiche, vale sempre la pena ascoltare. Nel loro portfolio ci sono aziende come:
Apple
Google
Airbnb
WhatsApp
NVIDIA
E quando descrivono un cambiamento strutturale del mercato, vanno ascoltati perché spesso stanno anticipando ciò che accadrà nel prossimo decennio.
Se i servizi sono il nuovo software
Se davvero i servizi saranno il nuovo software, allora servirà un luogo dove questi servizi AI possano:
nascere
essere distribuiti
essere utilizzati
essere monetizzati
Canonity prova a costruire esattamente questo: un posto dove chiunque può trasformare un’idea, un prompt o un workflow in un servizio AI eseguibile.
Perché il vero valore non è nel prompt, ma nell’esecuzione.
Ieri sera stavo leggendo un articolo su Lucy sulla cultura che parla dell’oblomovismo, quella sindrome tutta russa, dal romanzo di Gončarov del 1859, che descrive una pigrizia metafisica: l’incapacità di agire e di prendere decisioni. Il protagonista, Oblomov, non si alza dal letto per le prime centocinquanta pagine. Non perché sia stupido: ha studiato, ha conosciuto il mondo, si è convinto di potersi rendere utile alla patria. Ma la realtà si è mostrata troppo dura e lui si è ritirato progressivamente. Ha lasciato l’impiego, ha smesso di leggere, e passa le giornate a contorcersi tra le lenzuola.
E mentre leggevo, pensavo a una cosa che vedo ogni settimana.
Parlo con imprenditori, professionisti, gente che manda avanti aziende da vent’anni. Gli chiedo se stanno usando l’AI. Mi rispondono tutti allo stesso modo: “Sì, ho provato ChatGPT, ma non è granché per quello che faccio io.” Poi cambiano discorso. Come Oblomov che riceve i visitatori nel suo letto, un mondano, un impiegato, uno scrittore, ascolta tutti, annuisce, e non si alza.
Ecco il punto: non sono stupidi. Sono Oblomov.
La malattia è sistemica
L’articolo di Lucy racconta una cosa interessante. La critica russa dell’epoca non interpretò l’oblomovismo come un difetto individuale, ma come un tratto nazionale. Il critico Dobroljubov ci scrisse un saggio intero: una malattia congenita dello spirito russo che ostacolava il progresso. Non la pigrizia di uno, ma l’inerzia di tutti.
L’oblomovismo delle aziende italiane di fronte all’AI ha esattamente questa natura. Non è che il singolo imprenditore sia pigro. È che l’intero ecosistema, dalla formazione al rapporto con la tecnologia, dalla burocrazia alla cultura del “abbiamo sempre fatto così”, produce e riproduce torpore. Ognuno si è costruito la sua Oblomovka personale, la tenuta remota dove le regole del mondo esterno non arrivano. Il commercialista che dice “i miei clienti hanno bisogno del rapporto personale”. L’avvocato che dice “il diritto italiano è troppo complesso per una macchina”. Il manifatturiero che dice “noi facciamo cose fisiche, mica software”.
Ognuno ha le sue ragioni. Oblomov aveva le sue.
Quello che sta succedendo, raccontato da chi lo vive
Con grande senso della sincronia un mio amico ieri mi ha inoltrato un post di Matt Shumer, da sei anni alla guida di una startup AI, pubblicato su X che è diventato virale.
Ha scritto che ha smesso di dare la versione educata di quello che sta succedendo.
Il divario tra percezione pubblica e realtà è diventato troppo grande, e troppo pericoloso.
Il passaggio che mi ha colpito di più: Shumer racconta di descrivere un’applicazione in linguaggio naturale, andarsene dal computer per quattro ore, e tornare a trovare il lavoro finito. Non una bozza da correggere, il prodotto completo, migliore di quello che avrebbe fatto lui stesso. L’AI apre l’app, clicca i pulsanti, testa le funzionalità, itera come farebbe uno sviluppatore, e lo avvisa solo quando è soddisfatta del risultato.
Io scrivo codice da prima del Commodore VIC-20, quando avevo un Sinclair ZX81 con 1K di memoria e il BASIC si componeva premendo combinazioni di tasti. Ho certificazioni Microsoft degli anni ’90. So cosa vuol dire debuggare un segfault alle tre di notte. Eppure quello che Shumer descrive è esattamente quello che vivo anche io, ogni giorno, da mesi. Non è hype. Non è marketing. È la mia giornata lavorativa del lunedì.
Ma Shumer dice anche un’altra cosa che merita attenzione. Cita un managing partner di un grande studio legale che passa ore ogni giorno a usare l’AI. Non perché sia un giocattolo, ma perché funziona meglio dei suoi associati su molte attività. E ogni paio di mesi, diventa significativamente più capace. L’organizzazione METR, che misura la durata dei compiti che l’AI può completare autonomamente, un anno fa registrava circa dieci minuti. Oggi siamo a diverse ore. Ha raddoppiato i tempi in soli sette mesi e sta accelerando.
Al meetup di Milano che raccontavo nel mio ultimo post, ho visto un fotografo e un avvocato, nessuna formazione tecnica, costruire applicazioni funzionanti con l’AI. Non vibe coding: architettura, obiettivi, percorso. Competenza di dominio tradotta in prodotto, senza intermediari.
Mentre Oblomov resta a letto.
Il gusto del covo
La cosa che mi ha colpito di più nell’articolo di Lucy è un passaggio su Tommaso Landolfi e quello che chiamava “il senso della lustra”, il gusto del covo. Un piacere voluttuoso di chi si rintana nella propria casa in decadenza, mentre intorno tutto crolla. La casa crolla, sì, ma crolla lentamente, e nel frattempo ci si sta bene.
Questa è l’immagine più precisa che abbia mai trovato per descrivere quello che vedo nelle aziende italiane. L’inerzia non è solo paralisi, è comfort. I margini calano, la competitività si erode, i concorrenti che hanno agito guadagnano velocità e capacità di analisi, ma il covo è caldo. E ci si convince che il proprio settore sia speciale, immune, diverso.
Non lo è. Nessun settore lo è.
Oblomov si innamora di Olga, una donna che potrebbe salvarlo. Ma per sposarla dovrebbe rendersi degno della vita che lei rappresenta, e questo, scrive Gončarov, è una cosa che in pratica non si può fare, per quanto appaia realizzabile in teoria. Così Olga lo lascia e sposa Štolc, il tedesco positivo, il pragmatico. Oblomov riprecipita nel torpore. Sposa una donna che lo accudisce come un bambino. E muore di un colpo apoplettico.
L’azienda che rimanda non esplode. Diventa irrilevante un trimestre alla volta.
Alzarsi dal letto
Non scrivo questo per fare terrorismo psicologico. Lo scrivo perché il vantaggio più grande che potete avere in questo momento è semplicemente essere in anticipo. La finestra è ancora aperta: la maggior parte delle aziende italiane non si è mossa. Chi entra in una riunione e dice “ho usato l’AI per fare questa analisi in un’ora invece che in tre giorni” è la persona più preziosa nella stanza. Non domani, adesso.
Ma la finestra non resterà aperta a lungo.
“Addio vecchia Oblomovka”, dice Štolc alla fine del romanzo, “il tuo tempo è finito.”
Gončarov lo scrive con un pizzico di malinconia, credi che il mercato ne avrà alcuna?
La scelta è semplice, anche se non è facile: alzarsi dal letto, o aspettare il colpo apoplettico.
Photo by RDNE Stock project: https://www.pexels.com/photo/man-lying-on-sofa-beside-vacuum-5591469/
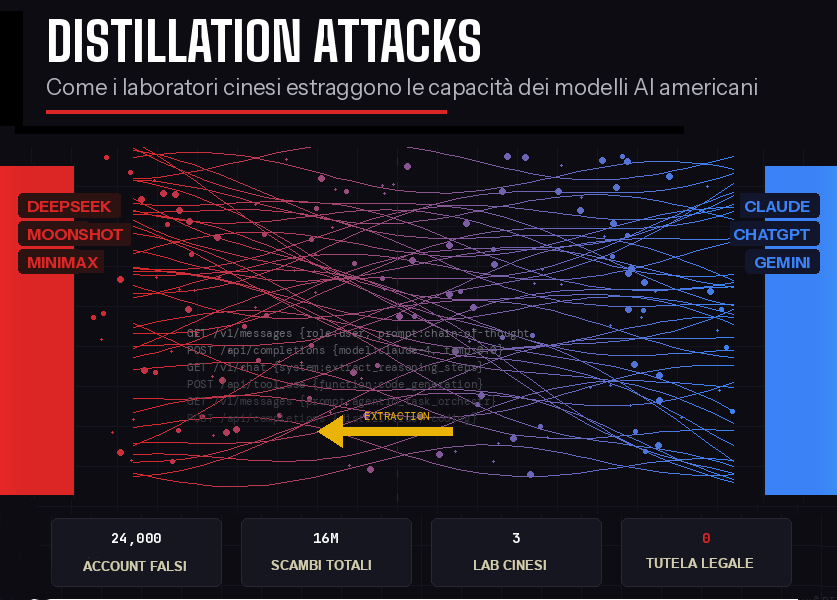
Oggi, 24 febbraio 2026, Anthropic ha pubblicato un report esplosivo: tre laboratori cinesi, DeepSeek, Moonshot AI e MiniMax, hanno condotto campagne di distillazione su scala industriale contro Claude.
I numeri fanno impressione: 24.000 account fraudolenti, 16 milioni di scambi con il modello. Non stiamo parlando di qualcuno che copia-incolla qualche risposta, ma di un’operazione sistematica e coordinata per estrarre le capacità di ragionamento, coding e uso di strumenti di uno dei modelli più avanzati al mondo.
Due settimane fa, OpenAI aveva denunciato la stessa cosa al Congresso americano riguardo a ChatGPT e Google ha segnalato oltre 100.000 prompt mirati su Gemini.
Il pattern è chiaro: i tre principali modelli americani sono sotto attacco simultaneo.
Come funziona la distillazione (in parole semplici)
La distillazione è una tecnica nota nell’AI: prendi un modello grande e potente (il “maestro”), gli fai migliaia di domande mirate, e usi le sue risposte per addestrare un modello più piccolo ed economico (lo “studente”).
Lo studente impara a imitare il maestro senza aver mai visto i dati originali di addestramento.
Geniale.
Le aziende AI la usano legittimamente tutti i giorni: Anthropic distilla Claude Opus per creare Claude Haiku, OpenAI distilla GPT-4 per creare GPT-4-mini.
È una pratica standard, ma il problema nasce quando un concorrente usa questa tecnica sui tuoi modelli, aggirando le restrizioni geografiche con servizi proxy, creando migliaia di account falsi, e generando milioni di query progettate per estrarre le capacità più avanzate. In sostanza: anni di ricerca e miliardi di dollari di investimento vengono compressi in poche settimane di scraping automatizzato.
I numeri dell’operazione
Secondo il report di Anthropic:
– DeepSeek: 150.000 scambi mirati su ragionamento logico e allineamento
– Moonshot AI: 3,4 milioni di scambi su ragionamento agentico, coding e computer vision (il loro modello Kimi K2.5, rilasciato il mese scorso, ne è probabilmente il risultato)
– MiniMax: 13 milioni di scambi su coding agentico e orchestrazione di strumenti
— Anthropic li ha colti in flagrante: quando è uscito un nuovo modello Claude, MiniMax ha rediretto metà del traffico nel giro di 24 ore per catturare le nuove capacitàTutte e tre le campagne seguivano lo stesso schema: servizi proxy commerciali per aggirare il blocco geografico della Cina, cluster di account distribuiti per evitare il rilevamento, e prompt strutturati per estrarre capacità specifiche — non le chiacchierate casuali di un utente normale.
Il vero problema: non c’è legge che funzioni
Ed è qui che la questione diventa strutturale. Perché la domanda che tutti si pongono è: “Ma non è illegale?”
La risposta, purtroppo, è molto meno chiara di quanto si vorrebbe.
Il copyright non si applica: L’U.S. Copyright Office ha stabilito che gli output generati dall’AI non raggiungono la soglia di “autorialità umana” necessaria per la protezione. Se le risposte di Claude non sono coperte da copyright, non puoi fare causa per violazione di copyright a chi le usa per addestrare un altro modello.
Paradossalmente, i Terms of Service di OpenAI cedono esplicitamente i diritti sugli output all’utente, rendendo ancora più difficile contestare l’uso che quell’utente ne fa.
I brevetti sono limitati: I brevetti potrebbero coprire architetture specifiche o processi, ma la distillazione non copia l’architettura — copia il comportamento. È come se qualcuno non rubasse il motore della tua Ferrari, ma guidasse la tua auto per migliaia di chilometri per capire esattamente come si comporta, e poi costruisse un’auto diversa che si guida allo stesso modo.
I Terms of Service valgono poco: Certo, Anthropic e OpenAI vietano esplicitamente la distillazione nei loro ToS. Ma provate a far valere un contratto americano contro un’azienda di Hangzhou o Shanghai. La giurisdizione è un muro. E anche se riusciste a portarli in tribunale, il danno è già fatto: il modello distillato è già stato addestrato e distribuito.
Il segreto commerciale è l’unica strada potenziale, ma richiede di dimostrare che l’azienda ha adottato misure ragionevoli per proteggere le informazioni e che c’è stato un accesso non autorizzato.
Quando il tuo prodotto è un’API pubblica e l’accesso avviene attraverso account apparentemente legittimi, la dimostrazione diventa molto complessa.
L’ironia della situazione
C’è un’ironia profonda in tutta questa vicenda, e la community online non ha mancato di farla notare: le stesse aziende che denunciano la distillazione dei loro modelli hanno costruito quei modelli addestrando su enormi quantità di contenuti altrui — libri, articoli, codice, immagini — spesso senza il consenso degli autori originali.
Anthropic stessa è sotto processo da parte degli editori musicali per aver usato testi di canzoni nell’addestramento di Claude.
È il classico “quando lo faccio io è innovazione, quando lo fai tu è furto.”
Questo non giustifica le campagne di distillazione su scala industriale, ma mette in prospettiva la fragilità delle argomentazioni legali: in un ecosistema dove tutti hanno costruito su dati altrui, tracciare una linea netta tra uso legittimo e furto è un esercizio giuridico senza precedenti.
Cosa succederà (probabilmente)
La soluzione non sarà legale, ma tecnica e geopolitica.
Sul fronte tecnico, Anthropic ha annunciato sistemi di behavioral fingerprinting e classificatori per identificare pattern di estrazione.
In pratica: se le tue query assomigliano a una campagna di distillazione e non a un uso normale, vieni bloccato. È una corsa agli armamenti continua, ma è l’unica difesa che funziona in tempo reale. Sul fronte geopolitico, queste denunce rafforzano la narrazione americana a favore di controlli più severi sulle esportazioni di chip AI verso la Cina. Se i modelli cinesi dipendono dalla distillazione di modelli americani per le loro capacità più avanzate, e la distillazione su scala richiede accesso a chip potenti, allora limitare i chip limita (anche) la capacità di distillazione.
La lezione per noi europei
Mentre americani e cinesi si confrontano sui modelli frontier, l’Europa guarda.
E questo è un problema, noi non abbiamo modelli frontier nostri su cui proteggere IP, non abbiamo chip di ultima generazione, non abbiamo le infrastrutture di compute necessarie.
L’AI Act europeo regola l’uso dell’AI ma non la produzione: come se regolassimo le automobili ma non avessimo fabbriche.
Se la distillazione diventa la normalità e l’unica protezione reale è avere qualcosa che valga la pena distillare. E per il momento, quel qualcosa ce l’hanno solo gli americani.
Nota: uso Claude quotidianamente nel mio lavoro e lo considero il miglior modello attualmente disponibile. Questo non cambia il fatto che la questione della distillazione sia oggettivamente complessa e che le ragioni non stiano tutte da una parte.
Voglio prendermi un momento per raccontarvi cosa stiamo costruendo, partendo da un esempio concreto che mi è capitato proprio oggi.
Tutto ha inizio quando un amico decide di imbarcarsi in una nuova avventura: un nuovo progetto per un nuovo prodotto. Come spesso accade a chi ha tra le mani un MVP (Minimum Viable Product), la prima cosa che ha fatto è stata battezzarlo con un nome che riteneva evocativo.
Tuttavia, la mia esperienza mi suggeriva che quella scelta non fosse quella giusta per il suo target e invece di dargli un semplice parere soggettivo, ho deciso di creare un workflow di prompt che aiutasse chiunque a capire se il nome scelto per il proprio business sia davvero quello corretto.
L’esperimento: 11 prompt e 5 modelli
L’idea è semplice: tu mi dici cosa fa il prodotto e come vuoi chiamarlo; io ti restituisco un’analisi approfondita di costi e benefici, fornendoti anche una “storia” da raccontare quando ti chiederanno il perché di quel nome.
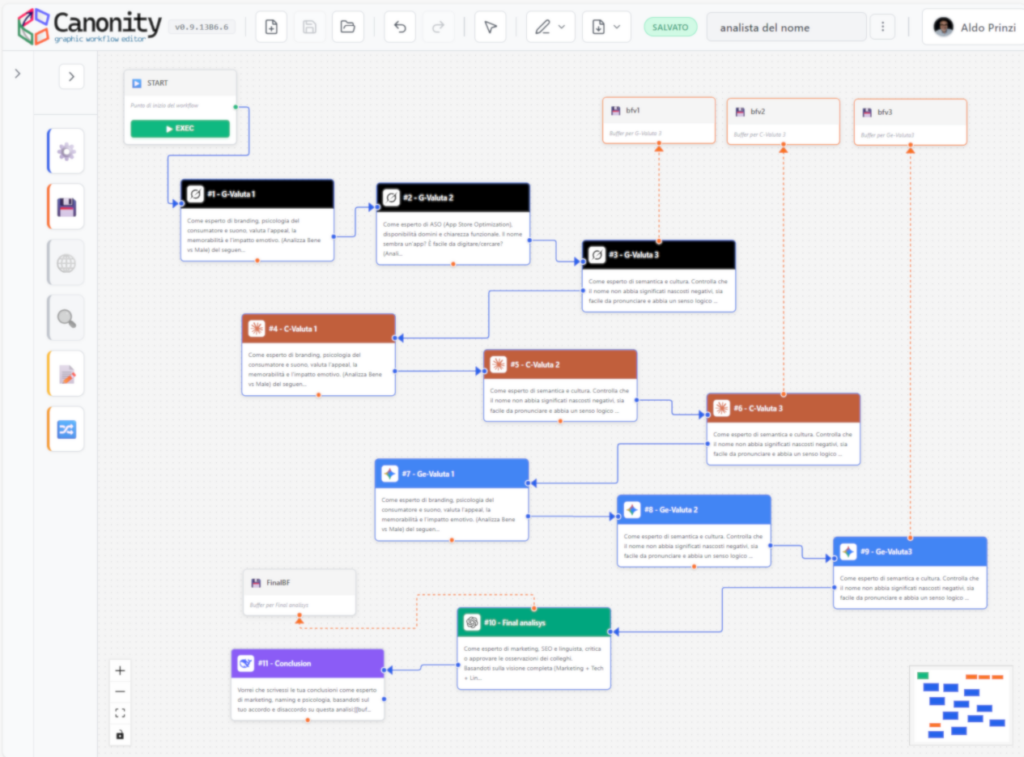
Per realizzare questa analisi, ho aperto Canonity, il nostro editor grafico di step-prompt e ho strutturato il lavoro in tre passaggi fondamentali:
Limitare le allucinazioni: Se chiedi troppe cose insieme a un’IA, tende a inventare ciò che non capisce, quindi ho diviso il processo di analisi in più step per aumentare drasticamente la precisione.
Il potere del confronto: Ho replicato i passaggi di analisi sfruttando la capacità di modelli diversi per avere più punti di vista. Ho sottoposto la prima analisi a Grok, la successiva a Claude e poi anche a Gemini.
Sintesi e Revisione: Infine, ho usato ChatGPT per riepilogare il tutto e DeepSeek per analizzare i pareri dei vari modelli e generare un riassunto finale.
In totale, l’analisi di un singolo nome è stata suddivisa in 11 prompt eseguiti da 5 modelli diversi che hanno collaborato tra loro.
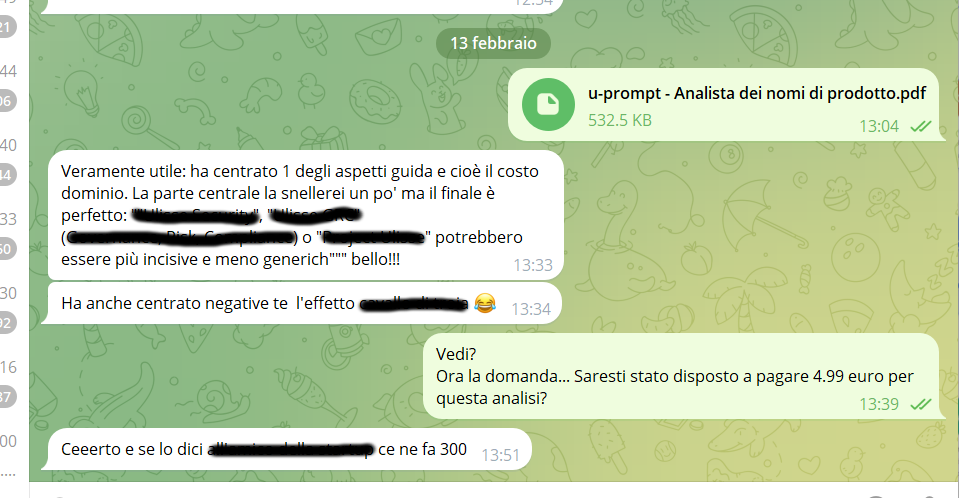
Ho stampato il PDF dopo averlo eseguito e l’ho inviato al mio amico che… ha validato l’utilità di questo prompt.
(Il sistema non si è limitato a dire se il nome fosse corretto, le tre cancellazioni in rosso erano tre esempi di nome alternativo più corretto, in relazione a ciò che quel prodotto fa) Del chè il messaggio del mio amico:
La prova del nove (anzi del 4,99)
La sua risposta è stata la migliore validazione possibile: non solo ha trovato l’analisi incredibilmente centrata — evidenziando aspetti critici come il costo del dominio o l’efficacia psicologica del nome — ma alla mia domanda provocatoria “Saresti stato disposto a pagare 4,99€ per questo?”, la risposta è stata un secco: “Ceeerto!”
Cosa sono, quindi, Canonity e u-prompt?
In poche parole:
Con Canonity ho realizzato l’applicazione (il workflow logico di analisi).
Attraverso u-prompt, ho messo in vendita l’esecuzione di quel workflow al prezzo di 4,99€.
E questo è solo uno dei workflow –> app. Il sistema ne gestirà centinaia, migliaia, ogni utente ne potrà avere quante ne vuole… Saranno di sua proprietà e non dovrà mai vendere il prompt, solo l’esecuzione.
Per esempio il nostro CEO, Stefano, sta già usando Canonity per disegnare un sistema che analizza i CV in relazione ai Job Post. L’app analizzerà l’annuncio, valuterà il tuo profilo/CV, ti suggerirà cosa enfatizzare e produrrà una lettera di presentazione adattata e su misura.
Una volta pronta, la metteremo in vendita su u-prompt a 2,99€.
Cosa ti serve per creare il tuo primo step prompt?
Serve conoscenza tecnica dello strumento? Si, c’è un tutorial che in 7 passi (5/6 minuti) ti spiega come funziona
Quale altra conoscenza tecnica serve? Nessuna, se hai scritto il prompt, premendo PLAY lo esegui e ottieni il risultato.
FINE.
Se vuoi capire come trasformare la tua competenza in un’app IA, o se hai domande su come funzionano i nostri strumenti, scrivici a hey [chiocciola] u-prompt.com.