Recentemente Sequoia Capital ha pubblicato un articolo molto interessante: “Services: The New Software”. (LINK)
La tesi è semplice ma dirompente: la prossima generazione di aziende AI non venderà software ma lavoro eseguito dall’intelligenza artificiale.
La prossima azienda da mille miliardi sarà un’azienda software che si presenta al cliente come un fornitore di servizi. Non vende il tool ma il lavoro fatto. Tu non compri il software di contabilità, compri la contabilità chiusa. Il software è sotto il cofano, il cliente vede solo il risultato.
La tesi è semplice ma dirompente: la prossima generazione di aziende AI non venderà software ma lavoro eseguito dall’intelligenza artificiale. In pratica per anni abbiamo costruito strumenti quali CRM, Contabilità, Tool di Marketing, tutti strumenti che aiutano le persone a fare il lavoro.
Adesso però l’AI cambia il paradigma, non si tratta più di software che aiuta a lavorare, si tratta di software che fa il lavoro, sia quello noioso e ripetitivo, sia quello di analisi.
Ma ogni founder si fa la stessa domanda: cosa succede quando la prossima versione di Claude o GPT, o Gemini rende il mio prodotto inutile? E ha ragione a preoccuparsi se vende lo strumento, ogni aggiornamento mangerà quote.
Ma se vendi il lavoro fatto, ogni miglioramento del modello rende il tuo servizio più veloce, più economico e più difficile da battere… E se i modelli sono più di uno la partita è vinta “a tavolino”.
L’AI ha imparato a parlare. Ora deve imparare a lavorare.
Il claim di Canonity nasce proprio da questa idea:
“L’AI ha imparato a parlare. È ora di insegnarle a lavorare.”
Negli ultimi anni abbiamo visto modelli sempre più capaci di conversare. Ma “chattare” non è lavorare, il vero salto avviene quando l’AI viene inserita in workflow capaci di produrre risultati concreti.
Sequoia divide il lavoro umano in due strati.
Intelligence è eseguire regole complesse: tradurre specifiche in codice, testare, fare debug. Le regole sono tante ma sono regole — l’IA le impara.
Judgement è decidere cosa costruire: quale feature ha priorità, se accettare debito tecnico, quando rilasciare anche se non è perfetto. Richiede esperienza, gusto, intuizione — anni di pratica.
Da prompt a servizi
Oggi chiunque può scrivere prompt o progettare workflow AI, ma questi prompt sono prodotti vendibili? No, sono semplicemente istruzioni.
Canonity prova a cambiare questo paradigma permettendo a chiunque di:
- creare un workflow AI
- pubblicarlo nel marketplace
- farlo utilizzare da altri
- guadagnare ogni volta che viene eseguito
Il punto chiave è questo: su Canonity non si vendono prompt.
Si vendono esecuzioni.
Alcuni esempi concreti? Immaginiamo alcuni servizi pubblicati nel marketplace Canonity.
Analisi CV e job posting
Un creator costruisce un workflow che:
- analizza un annuncio di lavoro
- analizza il curriculum del candidato
- identifica competenze rilevanti
- genera una lettera di presentazione personalizzata
L’utente carica CV e job posting, Canonity restituisce la lettera pronta e il creator guadagna ogni volta che il workflow viene eseguito.
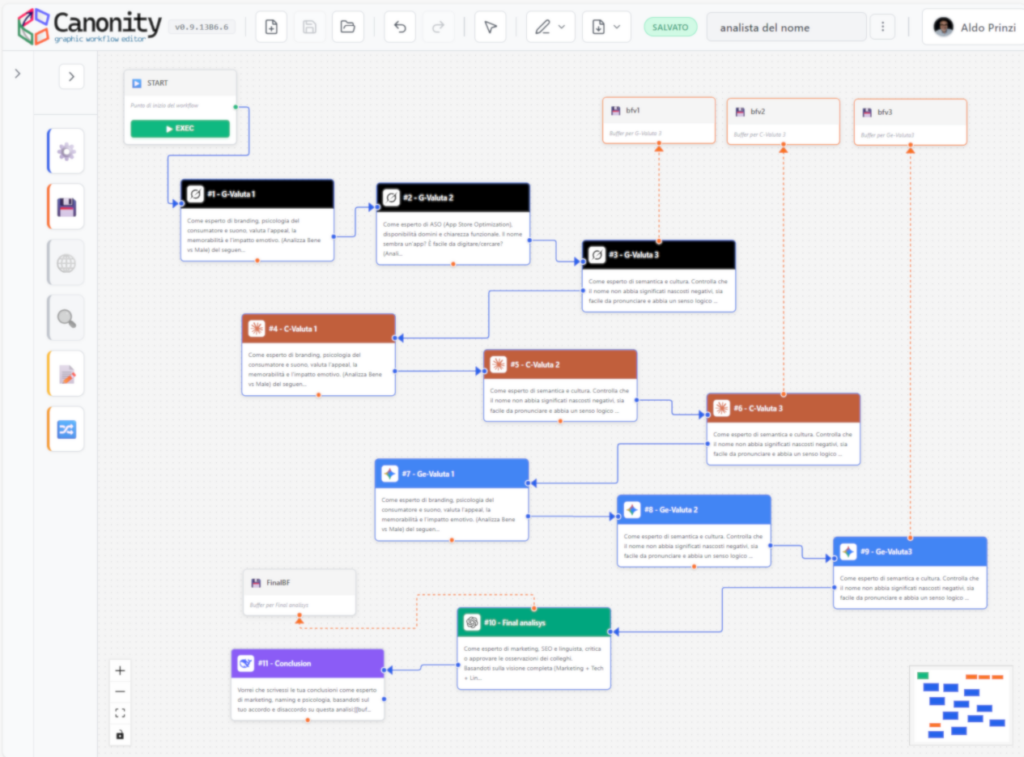
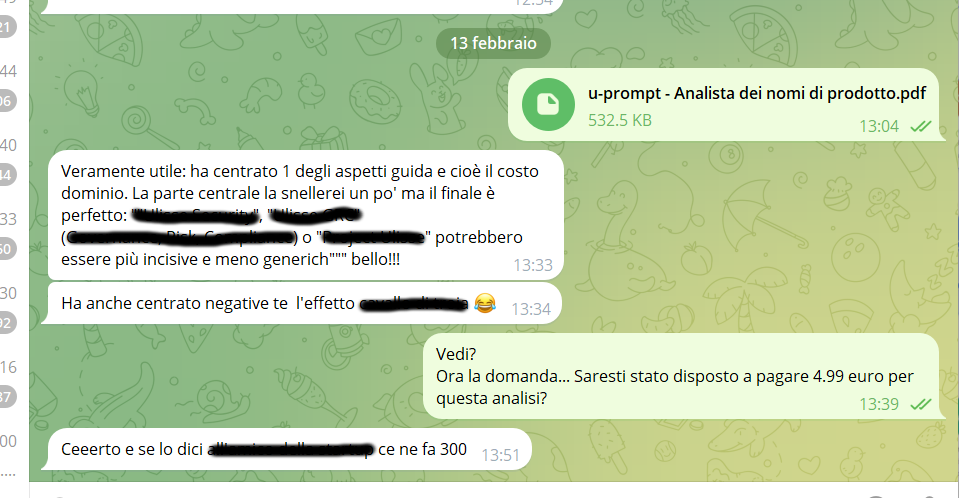
Analisi del naming di una startup
Un altro workflow potrebbe:
- analizzare il nome della startup
- confrontarlo con missione, prodotto e mercato
- valutare coerenza e memorabilità
- proporre alternative di naming più efficaci
L’utente non compra un prompt, ma l’analisi prodotta dall’esecuzione del workflow.I
La nascita di una execution economy
Molti marketplace AI oggi vendono:
- prompt
- template
- librerie di istruzioni
Canonity propone qualcosa di diverso: una execution economy.
Un luogo dove le persone pubblicano soluzioni AI
e vengono pagate per ogni utilizzo reale.
Perché ascoltare Sequoia
Quando Sequoia Capital parla di nuove categorie tecnologiche, vale sempre la pena ascoltare. Nel loro portfolio ci sono aziende come:
- Apple
- Airbnb
- NVIDIA
E quando descrivono un cambiamento strutturale del mercato, vanno ascoltati perché spesso stanno anticipando ciò che accadrà nel prossimo decennio.
Se i servizi sono il nuovo software
Se davvero i servizi saranno il nuovo software, allora servirà un luogo dove questi servizi AI possano:
- nascere
- essere distribuiti
- essere utilizzati
- essere monetizzati
Canonity prova a costruire esattamente questo: un posto dove chiunque può trasformare un’idea, un prompt o un workflow in un servizio AI eseguibile.
Perché il vero valore non è nel prompt, ma nell’esecuzione.