C’è una narrazione che va fortissimo su LinkedIn, nei keynote dei convegni tech e nei titoli acchiappa-click: l‘intelligenza artificiale sta eliminando i junior. Il coro è unanime. I dati sembrano dargli ragione, e come sempre, quando tutti sono d’accordo è il momento di fermarsi e guardare meglio.
Quello che emerge non è un problema tecnologico ma il fallimento del sistema formativo.
Perché no: l’AI non sta uccidendo i junior. L’AI sta facendo una TAC al mercato del lavoro. E la TAC mostra una malattia che c’era già — solo che prima non la volevamo vedere.
I numeri che tutti citano (e che nessuno contesta)
I dati sono reali, inutile negarlo: uno studio di Stanford sulla Digital Economy ha rilevato che l’occupazione degli sviluppatori software tra i 22 e i 25 anni è calata di quasi il 20% dal picco del 2022.
Il Bureau of Labor Statistics americano registra un calo del 27,5% nell’occupazione dei programmatori tra il 2023 e il 2025.
Le offerte di tirocinio nel tech sono crollate del 30% dal 2023.
Salesforce ha annunciato che nel 2025 non avrebbe assunto nuovi ingegneri junior.
Klarna ha congelato le assunzioni dev (per poi tornare sui propri passi, perché la strategia non funzionava).
Il 70% dei responsabili delle assunzioni in un sondaggio del 2024 ritiene che l’AI possa svolgere il lavoro degli stagisti. Il 57% si fida più dell’output dell’AI che di quello di un neolaureato.
Letti così, i numeri raccontano un’apocalisse, ma i numeri non raccontano mai tutta la storia.
Il gap che nessuno guarda: potenziale vs. realtà
A marzo 2026 Anthropic (non un osservatorio accademico, ma l’azienda che produce Claude) ha pubblicato uno studio illuminante: “Labor Market Impacts of AI: A New Measure and Early Evidence.”
I ricercatori Massenkoff e McCrory hanno introdotto un concetto nuovo: l’”observed exposure”, che confronta ciò che l’AI potrebbe teoricamente fare con ciò che effettivamente fa negli ambienti di lavoro reali, basandosi su milioni di conversazioni professionali con Claude.
Il risultato è un bagno di realtà: per le professioni informatiche e matematiche, l’AI è teoricamente in grado di gestire il 94% dei task.
Ma nella pratica ne copre il 33%.
Per le professioni amministrative, la capacità teorica è del 90% ma l’uso reale è una frazione.
I programmatori sono i più esposti con un 74,5% di copertura osservata, seguiti dal customer service (70,1%) e dal data entry (67,1%).
Ma il 30% dei lavoratori americani ha esposizione zero: cuochi, meccanici, baristi, bagnini, tutti mestieri che richiedono presenza fisica e che nessun LLM può replicare.
Il dato più interessante, però, è un altro: nonostante questa esposizione teorica massiccia, i ricercatori non hanno trovato un aumento sistematico della disoccupazione nelle professioni più esposte all’AI.
L’unico segnale d’allarme riguarda i lavoratori tra i 22 e i 25 anni, dove si registra un rallentamento delle assunzioni: che potrebbe però essere anche l’effetto residuo dell’over-hiring pandemico.
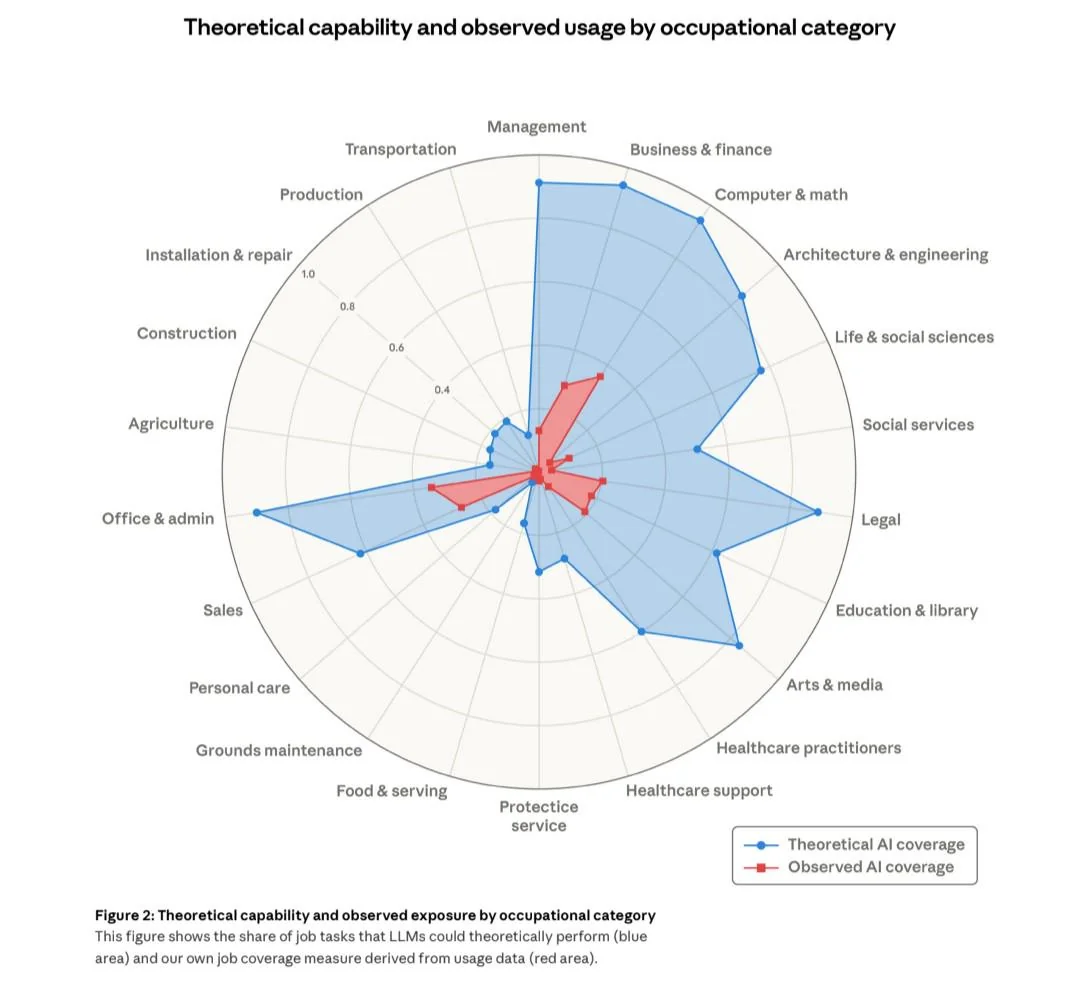
In altre parole: l’AI ha un potenziale enorme, ma l’adozione reale è ancora una frazione di quel potenziale. Il gap tra “blu” (cosa potrebbe fare) e “rosso” (cosa fa) è immenso. E le ragioni del gap non sono tecnologiche: sono limiti legali, necessità di supervisione umana, mancanza di integrazione software, lentezza organizzativa.
Questo ci dice qualcosa di fondamentale: il problema non è la velocità dell’AI, è la lentezza del sistema formativo ad adattarsi. L’AI si muove. Le università no.
La domanda che nessuno fa
Ecco la domanda scomoda, quella che nessuno vuole porre: se l’AI può sostituire un junior, quanto valeva davvero la formazione che quel junior aveva ricevuto?
Perché se un tool automatico è in grado di fare quello che fa un laureato con tre anni di università alle spalle, il problema non è il tool. Il problema è che quei tre anni non hanno prodotto competenze che un software non possa replicare.
E qui arriviamo al cuore della questione.
Il sistema formativo: l’elefante nella stanza
Il Cengage Group 2025 Graduate Employability Report è una lettura che dovrebbe togliere il sonno ai rettori di mezzo mondo. Mentre l’89% degli educatori è convinto che i propri studenti siano pronti per il mercato del lavoro, il 48% dei neolaureati dice di sentirsi impreparato anche solo per candidarsi a posizioni entry-level. Non per lavorare: per candidarsi.
Il 56% di chi si sente impreparato identifica nelle competenze tecniche specifiche la lacuna più grave.

E i dipendenti? Il 75% dichiara che le università non stanno preparando adeguatamente gli studenti. Il disallineamento è plastico: i datori di lavoro mettono al primo posto le competenze tecniche specifiche; gli educatori le mettono all’ultimo, preferendo concentrarsi sulle soft skills.
Risultato: solo il 30% dei laureati 2025 ha trovato un impiego nel proprio settore. Era il 41% appena un anno prima.
Negli Stati Uniti, il National Center on Education and the Economy ha rilevato che gli studenti passano il 60% del tempo in classe a prepararsi per test standardizzati, a scapito del problem-solving e dell’apprendimento basato su progetti.
McKinsey stima che le aziende spendano globalmente 3,4 miliardi di dollari l’anno in formazione “remediale” per dipendenti entry-level, per insegnare loro quello che avrebbero dovuto imparare a scuola.
L’Italia: il mismatch cronico
Se la situazione globale è preoccupante, quella italiana è strutturale.
Secondo il sistema Excelsior di Unioncamere, a fronte di 4,4 milioni di assunzioni programmate nel 2025, il mismatch tra domanda e offerta tocca il 47%. Per i laureati sale al 50,9%. Per i tecnici ITS al 57,3%.
Non sono numeri dell’era AI, sono numeri dell’era sempre.
Il Rapporto AlmaLaurea 2025 conferma: oltre il 30% dei neolaureati italiani lavora in settori non correlati al proprio titolo di studio. Il 46% degli studenti universitari e dei laureati ritiene che l’università non prepari adeguatamente al mondo del lavoro.
L’Italia è ventitreesima in Europa per competenze digitali: meno della metà della popolazione in età lavorativa (46%) possiede competenze digitali di base, e solo il 22% raggiunge un livello avanzato.
Il mismatch non l’ha creato ChatGPT. C’era quando si programmava in COBOL.
La truffa silenziosa: far pagare le aziende
Ecco il punto che nessuno dice ad alta voce: per decenni, il sistema formativo ha scaricato sulle aziende il costo di completare la formazione.
Il meccanismo era semplice e collaudato. L’università produceva laureati con una solida base teorica (nei casi migliori) ma con competenze operative vicine allo zero.
L’azienda poi assumeva il junior e doveva investire sei mesi, un anno, a volte due, per renderlo produttivo. Era una forma di sussidio implicito: il sistema educativo esternalizzava i propri fallimenti, e l’azienda pagava il conto senza discutere, perché non aveva alternative.
Adesso l’alternativa esiste? Secondo me si chiama AI.
Improvvisamente i conti non tornano più. Se per rendere produttivo un junior servono 12 mesi di investimento, e un tool di AI può coprire l’80% di quel lavoro dal giorno uno, la scelta economica è chiara. Non è cattiveria. Non è disumanizzazione. È aritmetica.
Ma la colpa è dell’AI? Oppure è di un sistema che ha prodotto junior il cui valore aggiunto era fare cose che una macchina poteva fare?
Il paradosso della pipeline
Qui si innesta un paradosso che InfoWorld e altri hanno evidenziato con lucidità: se le aziende non assumono junior, chi diventerà senior tra cinque anni?
È un problema reale, che nasce dalla stessa premessa sbagliata: l’idea che i junior servano per fare grunt work — il lavoro sporco, ripetitivo, il boilerplate — e che attraverso il grunt work, per osmosi, diventino senior.
Era un modello funzionale? Sì, più o meno.
Era efficiente? No.
Era l’unico possibile? Assolutamente no.
Se formiamo junior che sanno pensare a sistemi, che capiscono perché un’architettura è fatta in un certo modo e non solo come scriverla, che sono in grado di valutare quando l’AI ha ragione e quando sta generando spazzatura plausibile. Ecco che allora quei junior hanno un valore che nessun tool può replicare.
Il problema è che per formare junior così servono università e scuole che funzionino. E qui il cerchio si chiude.
Cosa dovrebbe cambiare (e non cambierà)
Il 2025 Stack Overflow Survey ha rivelato che il 66% degli sviluppatori è frustrato da soluzioni AI che sono “quasi giuste ma non del tutto.”
Questo è esattamente il punto: serve qualcuno che sappia quando la macchina sbaglia. Ma quella competenza — il pensiero critico, la comprensione profonda dei sistemi, la capacità di debugging architetturale — non si insegna con i test standardizzati.
Servirebbero curricula co-progettati con le aziende, stage reali, non finti, che sono inseriti nella preparazione scolastica: apprendimento esperienziale invece di lezioni frontali, insieme a integrazione della literacy AI fin dal primo anno.
Esattamente le cose che il sistema formativo, per inerzia burocratica, incentivi disallineati e autoreferenzialità accademica, non riesce a fare.
L’OCSE lo dice nel suo Skills Outlook 2025: i sistemi formativi devono permettere di muoversi più facilmente tra formazione e lavoro, tra percorsi vocazionali e accademici.
L’US Chamber of Commerce riporta che l’84% dei responsabili delle assunzioni ritiene i diplomati delle scuole superiori impreparati, e l’89% considera l’esperienza più preziosa dell’istruzione formale.
Chi lo sta già facendo (e funziona)
Se qualcuno pensa che riformare la formazione sia un esercizio teorico, si sbaglia. Ci sono realtà che lo stanno facendo adesso, con risultati misurabili.
Partiamo dagli estrem:
École 42 (Parigi, 50+ campus nel mondo) ha eliminato del tutto i professori: niente lezioni, niente rette, solo progetti e peer-to-peer learning.
Minerva University (San Francisco) ha eliminato aule e biblioteca, fa vivere gli studenti in quattro città del mondo, e i docenti non possono fare lezione per più di cinque minuti consecutivi. Sono modelli radicali, affascinanti, ma per definizione di nicchia. Non tutti possono — o devono — imparare senza una guida esperta.
I modelli più interessanti, e più scalabili, sono quelli ibridi: dove l’AI potenzia l’insegnante, non lo sostituisce. Dove la tecnologia gestisce la parte ripetitiva e personalizzata, liberando il docente per fare quello che solo un essere umano sa fare: guidare il ragionamento, creare contesto condiviso, far emergere i problemi comuni di una classe e affrontarli insieme.
Khan Academy / Khanmigo è l’esempio più avanzato di questo approccio.
Khanmigo, il tutor AI, è passato da 40.000 a 700.000 studenti K-12 in un solo anno scolastico (2024-25), con proiezioni oltre il milione.
La differenza rispetto a ChatGPT è strutturale: Khanmigo non dà risposte, guida lo studente a trovarle da solo, con il metodo socratico. Ma, e questo è il punto cruciale, funziona quando c’è un insegnante che supervisiona, che osserva i progressi, che interviene quando lo studente si blocca e che usa i dati della piattaforma per capire dove l’intera classe ha difficoltà.
Uno studio longitudinale di WestEd ha mostrato che gli studenti che usano Khanmigo almeno 30 minuti a settimana migliorano di 0,23 deviazioni standard in matematica. Per gli studenti non madrelingua inglese il guadagno sale a 0,31. La ricerca è chiara: i risultati migliori si ottengono quando AI e insegnante lavorano insieme, non quando uno sostituisce l’altro.
Il modello finlandese incarna lo stesso principio da decenni, senza bisogno di AI.
Niente test standardizzati fino ai 16 anni, insegnanti con master obbligatorio, selezionati tra i migliori studenti, apprendimento basato su progetti e fenomeni reali (“phenomenon-based learning”) dal 2016.
L’insegnante finlandese ha piena autonomia didattica e il suo ruolo è quello di facilitatore: non recita una lezione, crea situazioni in cui i problemi emergono e la classe li affronta insieme.
Nel 2018, l’Università di Helsinki ha lanciato con Reaktor “Elements of AI” per formare l’1% della popolazione sulle basi dell’intelligenza artificiale, non per sostituire gli insegnanti, ma per dare a tutti gli strumenti per capire cosa sta arrivando. Il tasso di transizione dalla formazione professionale al lavoro è del 78%, ben sopra la media UE.
ISDI di Madrid, la digital business school spagnola, integra reskilling continuo, apprendimento applicato e collaborazione stretta con l’industria. Circa il 90% dei laureati lavora in settori correlati ai propri studi entro sei mesi, in un mondo dove solo il 30% dei laureati americani trova lavoro nel proprio campo. E’ un numero che parla da solo!
Il filo comune? In tutti questi modelli l’insegnante non è un distributore di nozioni, ma un mentore che ti aiuta a ragionare, a contestualizzare, a riconoscere pattern. L’AI si occupa della ripetizione, della personalizzazione, del feedback immediato. L’umano si occupa del senso.
Lo stage non è un optional: le aziende devono stare dentro al sistema
C’è un ultimo pezzo che manca al puzzle, e senza il quale nessuna riforma funziona davvero: uno studente non è formato finché non ha messo piede in un’azienda vera.
Non parlo di stage cosmetici, quelli da tre mesi dove fai le fotocopie e ti dicono che stai “imparando la cultura aziendale.” Parlo di periodi strutturati, obbligatori, integrati nel curriculum, dove lo studente lavora su problemi reali sotto la supervisione di professionisti reali. E dove l’azienda, a sua volta, ha voce in capitolo su cosa insegna l’università.
Il Cengage Report 2025 lo dice in modo brutale: i laureati stessi riconoscono che le referenze personali (25%), i tirocini e l’esperienza lavorativa (22%) e le competenze di colloquio (20%) contano più della laurea in sé (17%) per trovare lavoro. Eppure il 20% dei laureati dichiara che il proprio percorso di studi non li ha aiutati a costruire una rete professionale. E il 35% avrebbe voluto che l’università collaborasse di più con le aziende.
La Finlandia lo fa da sempre: il 79,3% dei diplomati della formazione professionale ha svolto apprendimento in contesto lavorativo, contro una media UE del 65,2%.
École 42 include un tirocinio retribuito di 6 mesi obbligatorio nel percorso. ISDI costruisce i propri programmi in collaborazione diretta con le aziende.
Sono modelli in cui l’azienda non è il “cliente finale” che riceve il laureato a scatola chiusa — è un partner che co-progetta la formazione.
Pensateci: McKinsey stima che le aziende spendano 3,4 miliardi di dollari l’anno in formazione remediale per entry-level. È un costo che esiste perché il sistema formativo e il mondo del lavoro si parlano poco o niente. Se quei soldi, o anche una parte, venissero investiti prima — in stage strutturati, in co-design dei curricula, in docenti che vengono anche dall’industria — il risparmio sarebbe enorme e il prodotto finale incomparabilmente migliore.
Il concetto è semplice: la formazione non finisce con l’esame, finisce con il primo progetto reale consegnato a un cliente reale. Tutto il resto è teoria. E la teoria, da sola, è esattamente ciò che l’AI sa fare meglio di noi.

La morale della favola
L’AI non uccide i junior, ma l’illusione che una formazione inadeguata potesse restare nascosta sotto il tappeto per sempre.
Per decenni le aziende hanno fatto da ammortizzatore sociale, assorbendo silenziosamente il costo dei fallimenti formativi. L’AI ha semplicemente reso quel costo visibile… e inaccettabile…
Il vero nemico dei junior non è GPT-4, Claude o Gemini. Il vero nemico è un sistema educativo che produce laureati incapaci di fare quello per cui dovrebbero essere stati formati. E invece di riformare quel sistema, preferiamo dare la colpa alla tecnologia.
È più comodo, certo, ma non è onesto.
Fonti e dati citati:
- Stanford Digital Economy Study (2025)
- Anthropic — “Labor Market Impacts of AI: A New Measure and Early Evidence” (marzo 2026)
- U.S. Bureau of Labor Statistics (2023-2025)
- Cengage Group 2025 Graduate Employability Report
- Sistema Excelsior — Unioncamere/Ministero del Lavoro (2025)
- Rapporto AlmaLaurea 2025
- OECD Skills Outlook 2025
- U.S. Chamber of Commerce — New Hire Readiness Report 2025
- McKinsey & Company — Remedial Training Costs Analysis
- Stack Overflow Developer Survey 2025
- InfoWorld, IEEE Spectrum, CIO.com
- École 42 / 42 Network (42network.org)
- Minerva University — WURI Rankings 2022-2025
- Khan Academy Annual Report SY24-25 / WestEd Khanmigo Study
- OECD Digital Education Outlook 2026
- Center for Democracy and Technology — AI in Education Report 2025
- ISDI Madrid — Graduate Employment Data
- Finnish National Agency for Education / EU Education & Training Monitor 2025