Ogni tanto la tecnologia fa una cosa controintuitiva: invece di correre in avanti a testa bassa, si ferma, si gira e guarda indietro. Non per rimpiangere il passato, ma per ricordarsi come si costruiscono davvero le cose che durano.
È esattamente quello che è successo a novembre 2025 quando il Computer History Museum, insieme a Google, ha deciso di rendere pubblico il codice sorgente originale di AlexNet.
Il codice sorgente del 2012, quello che ha cambiato la storia dell’intelligenza artificiale.
Non è un’operazione nostalgica, e non è nemmeno un regalo per chi vuole “rifare AlexNet oggi”. È un gesto culturale. È come dire: prima di discutere dell’ennesimo modello miracoloso, forse vale la pena tornare a vedere come nasce una vera discontinuità tecnologica.
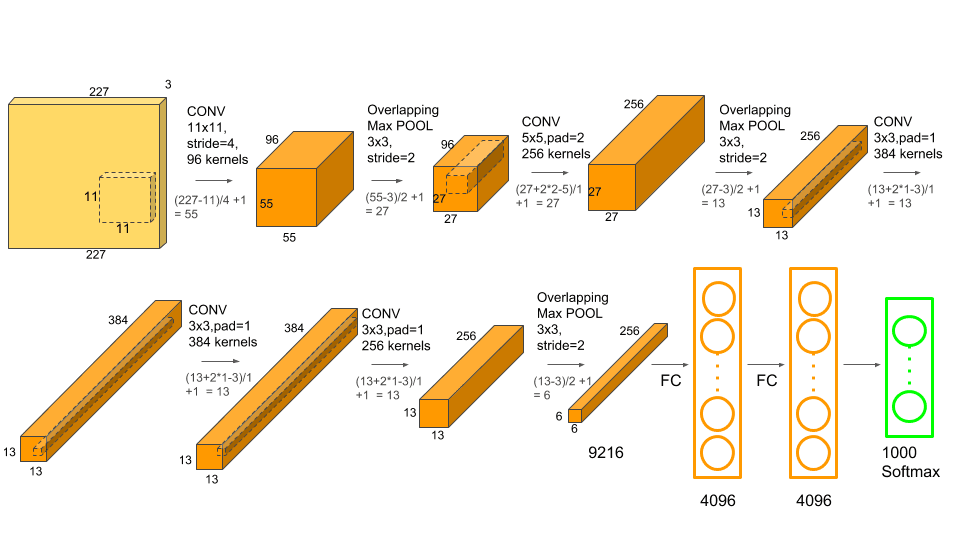
AlexNet nasce nel 2012 all’Università di Toronto, da Alex Krizhevsky, Ilya Sutskever e Geoffrey Hinton. Vince ImageNet in modo così netto da rendere improvvisamente obsoleti anni di approcci precedenti, dimostrando in un colpo solo che le reti neurali profonde non sono solo belle teorie: funzionano, scalano e cambiano le regole del gioco.
Da lì in poi il deep learning diventa la norma, le GPU diventano strumenti scientifici e la computer vision prende una direzione completamente nuova.
Ma oggi AlexNet non ci interessa per la sua potenza.
Oggi confrontata con gli standard attuali. Ci interessa per un motivo molto più profondo: come è stata pensata.
Il codice che oggi possiamo leggere su GitHub
🔗 https://github.com/computerhistory/AlexNet-Source-Code
Non è elegante, modulare, o “clean”. È scritto in CUDA C++ ed è brutalmente onesto. La memoria GPU viene gestita a mano, i layer non sono entità astratte ma strutture concrete, il training non è un loop astratto, ma è un flusso rigido e dichiarato. Non esiste separazione tra modello, training, preprocessing ed esecuzione: tutto è intrecciato, perché tutto fa parte dello stesso problema.
Leggerlo oggi è quasi uno shock culturale per chi è cresciuto a colpi di framework. Qui non c’è nulla che ti protegga. Se qualcosa non funziona, non puoi incolpare una libreria: sei tu. Ed è proprio questo che rende il codice di AlexNet così prezioso. Ti costringe a capire perché una scelta è stata fatta, quali compromessi sono stati accettati, quali limiti hardware hanno guidato l’architettura.
AlexNet, in altre parole, non era “solo un modello”. Era un sistema completo. Dataset, preprocessing, training su GPU, tuning manuale, gestione della memoria, flusso end-to-end. Tutto insieme. Nulla aveva senso da solo.
Ed è qui che il collegamento con l’IA di oggi diventa quasi imbarazzante per quanto è evidente.
Nel 2025 passiamo una quantità enorme di tempo a discutere su quale sia il modello migliore. Come se il problema fosse lì. Ma un singolo LLM, per quanto impressionante, soffre degli stessi limiti strutturali che avevano le singole reti neurali prima di AlexNet: non ha memoria vera, non ha visione di processo, non ha responsabilità sul risultato finale. Da solo, è fragile.
Il valore reale oggi emerge quando smettiamo di ragionare in termini di “modello” e iniziamo a ragionare in termini di sistema. Quando progettiamo flussi, step, ruoli, controlli. Quando decidiamo quale modello deve fare cosa, in quale momento, con quale contesto e con quale verifica. Quando l’intelligenza artificiale smette di essere una risposta brillante e diventa un processo governato.
AlexNet ci ricorda che le rivoluzioni non nascono da un singolo componente eccezionale, ma da un’architettura chiara. È lo stesso principio che oggi ritroviamo nei sistemi di orchestrazione multi-modello e, più in generale, in piattaforme come Canonity, dove il focus non è il prompt perfetto o il modello più grosso, ma la struttura che tiene tutto insieme. Non il singolo output, ma il flusso che lo rende affidabile.
AlexNet non ci colpisce più per la potenza, ma per la lucidità. Per il fatto che, prima che tutto diventasse automatico, qualcuno aveva capito che l’IA non è magia statistica, ma ingegneria dei sistemi. Il rilascio del suo codice non è una celebrazione del passato: è un promemoria molto attuale.
Se vogliamo davvero capire dove sta andando l’intelligenza artificiale, ogni tanto dobbiamo fare quello che fa questo repository: tornare alle fondamenta, sporcarci le mani con l’architettura e ricordarci che le vere innovazioni non nascono dall’ultimo modello, ma dalla capacità di mettere ordine nella complessità.

